Was ist das Crawl Budget?

Gute Rankings in den Google Ergebnissen sind das zentrale Ziel der Suchmaschinenoptimierung. Aber wie kommt es überhaupt dazu, dass Google weiß, welche Inhalte relevant für die Nutzer sind? Wir erklären, wie Google den Content von Websites analysiert und was das Crawl Budget damit zu tun hat. Zusätzlich geben wir wertvolle SEO-Tipps, mit denen das Crawl Budget, das Google einer Website zur Verfügung stellt, optimal für gute Rankings ausgenutzt wird.
Google Crawler erklärt
Wird eine neue Seite mit neuem Content online gestellt oder werden bestehende Texte auf einer Website überarbeitet, scannen die Googlebots diese Inhalte. Googlebots sind sogenannte Crawler, d.h. automatisierte Programme, die regelmäßig mobile und Desktop-Versionen von Websites durchforsten. Von diesen Bots wird die Seite mit den neuen oder veränderten Inhalten von der Suchmaschine indexiert. Sind die Texte und Inhalte indexiert, bedeutet das, dass sie in der Google Suche auffindbar sind. Die Crawl-Bots führen diesen automatisierten Prozess regelmäßig aus.
Der Ablauf einer Google Suche lässt sich in drei Phasen gliedern, beginnend mit dem Crawling.

Crawling der Seite
Der Googlebot-Crawler besucht eine Website. Er liest Angaben aus Meta-Tags oder der robots.txt-Datei aus, für alle Seiten, für die sein Crawl Budget ausreicht. Der Crawler folgt allen eingehenden, ausgehenden Links und durchsucht Inhalte, Daten, Sitemaps der Seite. Diese Daten speichert er in seinem Cache: Er lädt Medien wie Texte, Bilder und Videos temporär herunter, um sie an den Index weiterzugeben.

Indexierung

Suchanfrage und SERPs
Wenn Nutzer ein Keyword als Suchanfrage eingeben, gibt Google Informationen zurück, die nach Kriterien des Google-Algorithmus für dieses Keyword als relevant bewertet werden. Hunderte von Faktoren fließen in diese Entscheidung ein – nicht nur die Inhalte der verfügbaren Seiten, sondern auch Standort, Sprache und Gerät des spezifischen Nutzers. Beantwortet ein Text alle relevanten Fragen der Nutzer, ist es wahrscheinlicher, dass die Website unter den Top-Ergebnissen aufgelistet wird.
Definition: Crawl Budget
Was hat der Crawl-Prozess denn nun mit einem Budget zu tun? Ganz einfach:
Der Googlebot durchsucht das Internet, um Webseiten zu entdecken, zu analysieren und zu indizieren, damit diese in den Suchergebnissen angezeigt werden können. Um diese umfangreiche Aufgabe effizient zu bewältigen, verfügt jeder Crawler über eine begrenzte Menge an Ressourcen, die er für das Durchsuchen und Analysieren von Webseiten verwenden kann. Diese Ressourcenbegrenzung ist als das „Crawl Budget“ bekannt.
Google und andere Suchmaschinen bestimmen das Crawl Budget einer Website anhand verschiedener Faktoren, wie z. B. der Qualität und Aktualität des Inhalts, der Serverleistung und der Verlinkungsstruktur. Je größer das Crawl Budget einer Seite, desto mehr Zeit nimmt der Web-Crawler in Anspruch, um eine Seite zu erfassen.
Es ist deshalb wichtig, sicherzustellen, dass die wichtigsten Seiten einer Website für Suchmaschinen leicht zugänglich sind: Behindern unnötige Hindernisse den Crawl-Prozess, werden die Ressourcen des Crawlers nicht effektiv genutzt. In solchen Fällen kann es sein, dass neue Unterseiten oder Änderungen an einer Website längere Zeit nicht gecrawlt und nicht in Googles Index aufgenommen werden – so können sie nicht in den Suchergebnisseiten auftauchen. Bei solch einer Optimierung der Website-Performance spricht man von technischem SEO.
Exkurs: Fresh Crawl vs. Deep Crawl
Der Googlebot führt dauerhaft Website-Scans durch, um die Fragen der Nutzer immer mit den aktuellen Informationen beantworten zu können. Dazu führt er fast täglich einen Fresh Crawl für aktuelle Änderungen auf einzelnen Seiten durch und ungefähr monatlich einen Deep Crawl für die Analyse der gesamten Website.
| Fresh Crawls | Deep Crawls |
|---|---|
|
|
|
|
|
|
|
|
So lässt sich das Crawl Budget prüfen
Da gute Platzierungen nur dann erzielt werden können, wenn Inhalte vom Googlebot gefunden, analysiert und im Google Index aufgenommen werden können, lohnt es sich, das Crawling und die Indexierung einer Website immer im Blick zu behalten.
Das Crawl Budget, also die Ressourcen, die für das Crawlen und die Indexierung zur Verfügung stehen, lassen sich leider nicht direkt einsehen. Dennoch liefert die Google Search Console wertvolle Insights in den sogenannten Crawling-Statistiken.
Diese drei Dinge solltest du prüfen, um dein Crawl-Budget zu optimieren:
- Gab es durch den Googlebot Verfügbarkeitsprobleme auf der Website?
- Gab es Seiten, die nicht gecrawlt wurden/werden, obwohl sie es sollten?
- Werden meine (neuen) Inhalte schnell genug gecrawlt?
Diese Fragen lassen sich mithilfe der Search Console ganz einfach beantworten.
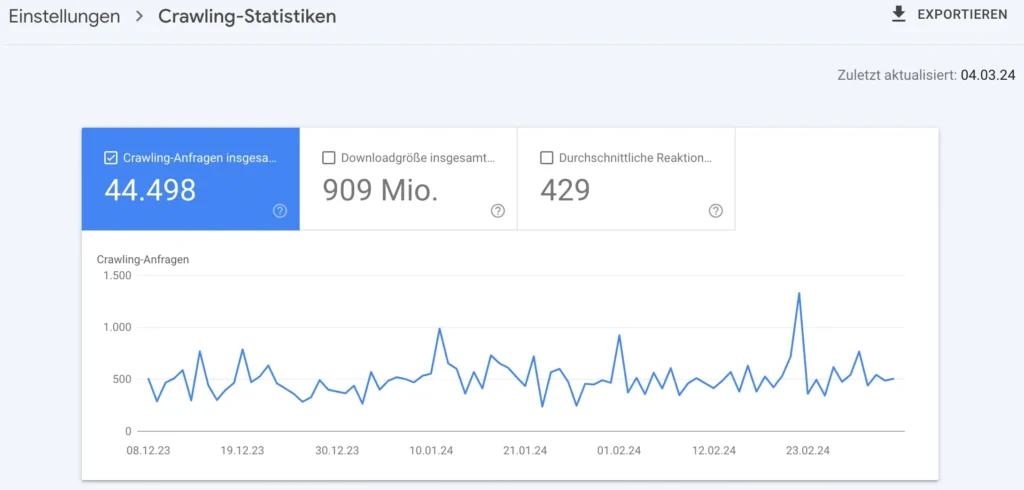
Anleitung: Website Crawl Statistiken einsehen
- In der Google Search Console anmelden
- Im Bereich “Vorherige Tools und Berichte” die Einstellungen öffnen
- Dort die “Crawling-Statistik” auswählen
- Das erste der drei verfügbaren Diagramme zeigt die Anzahl der gescannten Seiten pro Tag (hier als “Total Crawl Requests”). Hat eine Website viele Landing Pages, die indexiert werden sollen, müsste die Anzahl der Crawl-Anfragen möglichst hoch sein.
Die beiden weiteren Diagramme zeigen die Menge der täglich heruntergeladenen Daten und die Ladezeiten. Hinsichtlich der technischen Optimierung einer Seite sind diese Werte möglichst gering zu halten. Zusätzlich werden bei einem geringeren Zeitaufwand zum Herunterladen der Daten wiederum mehr Unterseiten gecrawlt.
Weitere Tools
- Screaming Frog: Ein beliebtes Desktop-Tool, mit dem sich der Crawling-Prozess einer Website simulieren lässt. Es zeigt durch Crawling-Audits, wie Suchmaschinen Seiten durchgehen und identifiziert mögliche Probleme wie fehlende Metadaten oder fehlerhafte Weiterleitungen, d.h. Broken Links oder falsche Verweise, die den Crawler in eine Sackgasse oder Weiterleitungsschleife senden.
- Lumar (ehem. DeepCrawl): Ein umfassendes Crawling-Tool, das Crawling-Statistiken und die Website Performance überwacht und Fehler identifiziert. Lumar bietet nicht nur Vorschläge für die Crawling Budget Optimierung, sondern prüft ebenso die Barrierefreiheit der Website – ebenfalls ein wichtiger SEO-Faktor, um Mehrwert für alle Nutzer bieten zu können.
- Botify SiteCrawler: Als Teil des Botify SEO-Dienstes bietet das Tool zur Überwachung des Crawling-Prozesses umfangreiche Daten und Analysen, um die die Arbeit der Crawler zu simulieren und die Leistung von Websites zu steigern.
Unterschied: Crawl Budget und Index Budget
Anders als das Crawl Budget gibt das Index Budget nicht an, wie viele Seiten generell von Google gescannt werden, sondern wie viele Unterseiten einer Domain indexiert und somit über die Google Suche auffindbargemacht werden.
Um das Index Budget und das Crawl Budget einer Seite sinnvoll zu nutzen, sind Seiten mit 404-Fehlercode oder weitere fehlerhafte Statuscode zurückliefern, dringlichst zu vermeiden, da das Budget auf diesen Seiten nur verschwendet wird.
Google Crawl Budget optimieren
Wer gute Platzierungen in den Google Suchergebnissen zu relevanten Keywords anstrebt, sollte das Crawl Budget bei der Suchmaschinenoptimierung nicht vernachlässigen. Es ist nicht nur so, dass eine optimierte Seite effizienter gecrawlt wird und dies die Rankings positiv beeinflusst: Eine Website mit vielen guten Platzierungen sorgt dafür, dass wiederum das Crawl Budget gesteigert wird. Google erkennt, dass die Inhalte der Website hilfreich für Seitenbesucher sind und investiert daher mehr Zeit in den Scan der Website. Die Suchmaschine entscheidet für jede Website flexibel anhand ihrer variablen Crawling-Kapazitätslimit und Crawling-Bedarf, welches Budget dem Crawler zur Verfügung steht.
Was ist das Crawling-Kapazitätslimit?
Das Kapazitätslimit beschreibt, wie viele Verbindungen der Crawler gleichzeitig prüfen darf: Reagiert eine Website schnell und problemlos auf Aufrufe, können mehrere Unterseiten gleichzeitig gecrawlt werden. Ist die Website langsam, nimmt der Bot sich Unterseiten nur nacheinander vor – dann werden insgesamt weniger Seiten geprüft. Deshalb ist es wichtig, zur Optimierung der Nutzung des Crawl Budgets einen Fokus auf schnelle Ladezeiten und fehlerlose Abläufe auf der Website zu legen. Ein Anhaltspunkt für das Crawling-Kapazitätslimit sind die Core Web Vitals der Seite. Diese Kennzahlen sind ein bedeutender Ranking-Faktor bei Google, der u. a. auch die Ladegeschwindigkeit einer Seite betrachtet.
Was ist der Crawling-Bedarf?
Google betrachtet mehrere Faktoren, die dazu führen können, dass eine Website häufiger oder ausführlicher gecrawlt wird. Einen gesteigerten Crawling-Bedarf empfinden Crawler z. B. bei Websites, die sehr beliebt sind (d. h. wahrscheinlich: einen hohen Traffic und eine starke Domain Rate haben) oder die häufig mit neuem Content oder neuen Landingpages aktualisiert werden. Ist eine Website voller veraltetem Content, hat eine verwirrende, nicht nutzerfreundliche Seitenstruktur oder Inhalte, die sich doppeln (sog. Duplicate Content), so sieht der Crawler keinen großen Bedarf, wiederzukommen, und verschwendet beim Crawlen zusätzlich noch sein Budget. Somit ist bei der Crawl Budget Optimierung ein Blick auf den Inhalt und die Seitenstruktur zentral.
Tipps zur Optimierung des Crawl Budgets:
- Interne Verlinkungen zwischen Texten nutzen, um den Crawler auf weitere Unterseiten zu lenken. Seiten mit vielen internen Verlinkungen von Google werden positiver bewertet. Allerdings sollte zwischen zwei Seiten nicht häufig hin- und zurück-verlinkt werden, da der Crawler durch das Vor- und Zurückgehen unnötig Ressourcen verschwenden würde.
- Regelmäßig neuen und relevanten Content veröffentlichen, zusätzlich bestehenden Content regelmäßig überarbeiten und aktualisieren. Mit dem Tag “lastmod” können Seiten in ihrem Quelltext als frisch bearbeitet markiert werden, damit der Crawler diese veränderten Seiten zuerst berücksichtigt.
- Duplicate Content unbedingt vermeiden: Wenn Content sich auf einer Seite doppelt, können Crawler Inhalte nicht eindeutig zuordnen und das Seitenranking wird herabgesetzt.
- Das Linkbuilding nicht vernachlässigen. Hochwertige Backlinks steigern die Autorität einer Seite, sodass Crawler diese besser einschätzen und häufiger besuchen.
- Den Seitenaufbau flach halten, indem wichtige Seiten schnell über die Startseite erreichbar sind. So verschwenden die Crawler weniger Budget durch den Wechsel zwischen zu vielen Unterseiten.
- Externe Verlinkungen auf “nofollow” setzen, um den Googlebot vom Absprung auf externe Seiten abzuhalten.
- In der Robots.txt irrelevante Seiten vom Crawling ausschließen, die nicht im Google Index auftauchen sollen – z. B. Warenkörbe oder Bezahlprozesse in Online Shops, oder Seiten mit Duplicate Content, die das Ranking senken würden.
- Eine eindeutige XML-Sitemap mit einer Übersicht über die wichtigsten URLs hinterlegen, damit Crawler die Seitenstruktur schnell begreifen.
No-Gos im Umgang mit Crawlern
Neben den oben genannten gibt es einige weitere Möglichkeiten, den Crawler durch Hinweise im Seitenquelltext zu steuern. Allerdings sind diese nicht immer effektiv in der Optimierung von Websites für eine maximale Nutzung des Crawl Budgets und es gibt einiges zu beachten.
- noindex Tag verwenden, aber URL steht in der Sitemap: Ist eine Seite noch nicht fertiggestellt, nicht relevant für das Ranking, oder nicht für die Öffentlichkeit bestimmt, können durch den “noindex” Tag die Crawler gebeten werden, die Seite nicht zu indizieren. Prinzipiell ist dies eine weitere gute Möglichkeit, das Crawl Budget effektiv einsetzen zu lassen – ein No-Go ist hierbei jedoch, eine Seite zwar mit noindex zu markieren, die Seite aber in der XML-Sitemap stehenzulassen. In diesem Fall kann der Crawler keine eindeutige Entscheidung treffen, ob die Seite indexiert werden soll.
- Umleitungen in der Robots.txt: Im Google Ratgeber zum Managen von Crawl Budget weist Google darauf hin, dass es nicht möglich sei, Crawler durch Hinweise in der Robots.txt von einer Seite auf eine andere umzuleiten, damit das Crawl Budget nicht für Erstere eingesetzt wird. Seiten könnten in der Robots.txt-Datei vom Crawling ausgeschlossen werden, der Crawler würde die weitere Verwendung seines Budgets dann aber frei entscheiden, sodass gezielte Umleitungen nutzlos sein.
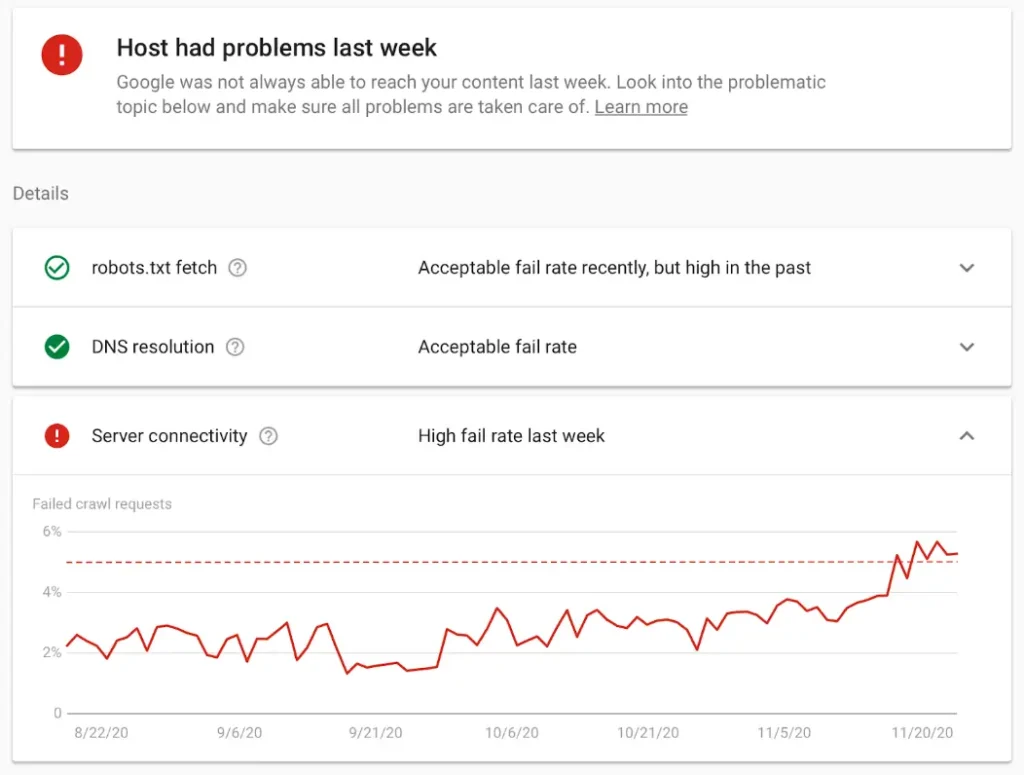
- Verlinkung nicht-existenter Inhalte: Fehlerhafte Verlinkungen, die ins Nichts führen, können unnötiges Crawl-Budget schlucken. Die Search Console ist ein mächtiges Tool, um diese aufzudecken: “Service nicht verfügbar” (503-Fehler), “Forbidden” bzw. Zugriff verweigert (403 Fehler) und “Seite nicht gefunden” (404-Fehler) sind die gängigsten Fehlermeldungen, die direkt in der Search Console für eine Domain aufgezeigt werden – beispielhafte Fehlerhinweise siehe in der Abbildung oben.
Fazit
Die internen Vorgänge und Beurteilungskriterien der Googlebots sind für Laien oft schwer und wenig transparent. Trotzdem ist es sinnvoll, sich mit dem Crawl Budget einer Website auseinanderzusetzen, um gute Platzierungen in den SERPs zu erreichen. Wer die genannten Strategien für die Crawl Budget Optimierung und technische SEO beachtet, kann dafür sorgen, dass Google seiner Seite mehr Beachtung schenkt und so die Chance auf Top-Platzierungen für relevante Suchbegriffe erhöhen.
Sie fragen sich, wie gut Ihre Seite für die Googlebots zugänglich ist und ob sie das Crawl Budget sinnvoll nutzen? Als SEO-Agentur verhelfen wir Ihrer Seite zu mehr Sichtbarkeit. Wir optimieren Inhalte, Seitenstrukturen, Backlinks & Co. – mit langjähriger Erfahrung und voller Transparenz. Vereinbaren Sie jetzt einen Beratungstermin und wir analysieren Ihre Seite auf SEO-Potenziale.

