Indexierung
Bei der Eingabe bestimmter Schlüsselbegriffe in eine Suchmaschinenmaske werden uns Inhalte angezeigt, welche für diese Keywords relevant sind. Startet ein Nutzer eine Suchanfrage, durchsuchen Google und Co. ihren Index, um dem User wertvolle Suchergebnisse anzuzeigen, die ihm einen Mehrwert bieten. Der Begriff der Indexierung bezieht sich hierbei auf die Methode der Informationserfassung. Bestimmte Informationen werden demnach in einen Index aufgenommen und nach spezifischen Kriterien sortiert.
Was ist ein Index?
Ein Index lässt sich als geordnetes Verzeichnis definieren. Als eine Art komplexes Register oder Nachschlagewerk lässt es sich mit Lexika oder Telefonbüchern vergleichen. Die Indexierung beschreibt dabei die Aufnahme von Informationen und Inhalten in einen Index. Mit diesem kann eine rasante Auffindbarkeit von Informationen sichergestellt werden.
Der Google Index – wie wird er gefüllt?
Die Masse aller von Google erkannten (gecrawlten) und abgespeicherten, also indexierten Websites wird als Google Index bezeichnet. Suchmaschinen wie Google, Yahoo oder Bing nutzen Crawler für die Indexierung. Ist eine Website nicht im Index, erscheint diese nicht in den SERPs. Denn die SERPs enthalten ausschließlich jene Seiten aus dem Index.
Dabei ist der Google Index weder statisch noch ein klassisches Lexikon. Dynamik spielt eine große Rolle – stetig werden von den Crawlern neue Seiten erfasst und hinzugefügt, andere Seiten werden wiederum entfernt. Diese sogenannten Robots oder Bots arbeiten autonom und nehmen dabei Seite für Seite unter die Lupe. Wird eine Website gecrawlt, dann liest der Bot den Quellcode aus und leitet diesen an den Index weiter.

Die Inhalte von Websites werden durch Crawler nicht nur gelesen und in den Index aufgenommen, sondern werden dabei im Index sortiert. Diese Sortierung erfolgt anhand von verschiedenen Kriterien und einem Algorithmus, der darüber entscheidet, in welcher Reihenfolge der Nutzer die Websites in den Suchergebnissen sieht.
Suchmaschinenanbieter wie Google arbeiten stetig an der Weiterentwicklung dieser Algorithmen für die Indexierung, sodass den Nutzern ausschließlich relevante Inhalte schnell und effizient zur Verfügung gestellt werden können. Wie genau der Index aufgebaut wird und welche Änderungen am Algorithmus im Detail vorgenommen werden, ist allerdings ein Betriebsgeheimnis von Google. Fakt ist: Wird gegen die Google Richtlinien verstoßen, droht die Entfernung der Website aus dem Index und somit auch aus den SERPs.
Wie kann ich eine Website indexieren?
Eine Seite kann direkt an Google gesendet werden, wenn diese (neu)indexiert werden soll. Dafür kommen folgende zwei Möglichkeiten infrage:

Mit der Google Search Console kann eine Sitemap direkt an Google gesendet werden. Dabei wird die Sitemap im .xml Format erstellt und in der Search Console eingereicht. Die darin enthaltenen URLs crawlt Google im nächsten Schritt. Diese Möglichkeit ist für mehrere URL-Updates (inhaltliche Aktualisierungen sowie neue URLs) gedacht.
In der Google Search Console kannst du einsehen, wie viele Seiten deiner Website bereits indexiert bzw. nicht indexiert sind.



Sind nur wenige Änderungen vorgenommen worden und sollen demnach nur ein paar wenige einzelne URLs indexiert oder neu gecrawlt werden, kannst du das URL Inspection Tool nutzen. Praktisch ist dies vor allem, wenn eine Seite hinzugekommen ist, nachdem die Sitemap bereits erstellt wurde. Allerdings wird dabei nur diese URL und möglicherweise auf dieser Seite verlinkte Seiten neu gecrawlt. Mit dieser Variante bittest du die Suchmaschine nur darum, die jeweilige einzelne Seite neu zu crawlen.
Die Indexierung von einzelnen URLs läuft wie folgt ab:
1. In der Schaltfläche oben wird die zu indexierende URL eingegeben.

2. Kurz warten (bis zu wenigen Minuten), denn die Daten werden aus dem Google Index abgerufen.
3. Es erscheint die Meldung, ob die Seite indexiert ist oder nicht. Wenn die URL neu ist oder auf der Seite etwas geändert wurde, kann die Indexierung beantragt werden.
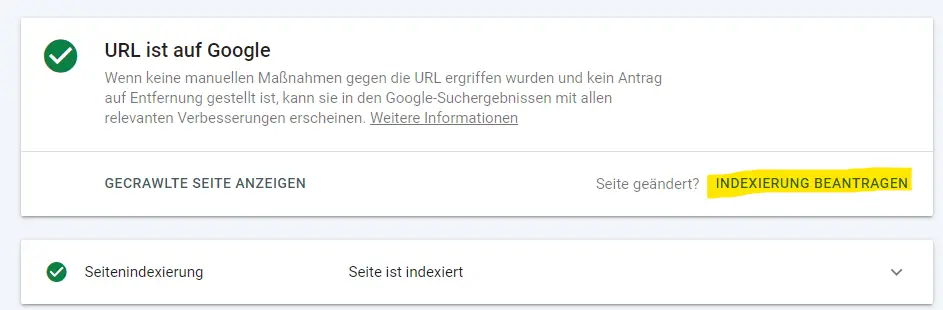
4. In dieser Abfrage erhältst du außerdem viele Informationen über die URL.

Beachte dabei, dass für das Einreichen einzelner URLs ein Kontingent für jedes Nutzer-Konto besteht. Dieses beschränkt die Anzahl der URLs, welche an den Index gesendet werden können. Die Usage Limits geben Auskunft darüber, dass pro Nutzer nur eine bestimmte Anzahl an Queries eingereicht werden kann. Eine exakte Ziffer für das bestehende Kontingent, also für das Einreichen von einzelnen URLs, gibt Google nicht bekannt. Unsere Erfahrung zeigt, dass ein Nutzer etwa 20 URLs pro Woche einreichen kann.
Wie überprüfe ich den Google Index meiner Seite?
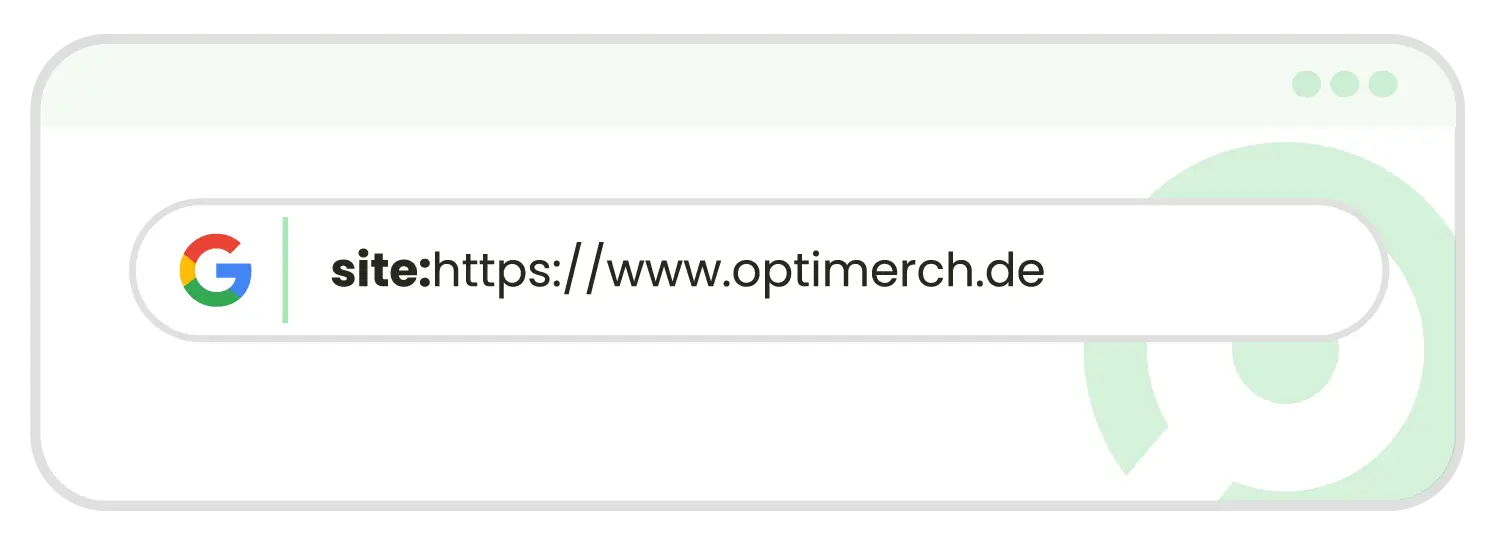
Der Index-Status einer Seite kann nicht nur in der Search Console eingesehen und abgerufen werden. Auch kann manuell und ohne großen Aufwand geprüft werden, wie viele URLs einer Website sich im Google Index befinden. Per Site-Abfrage erhält man eine Auflistung sämtlicher Unterseiten, welche zu einer Domain im Index zu finden sind. Hierbei wird wie bei einer gewöhnlichen Suche der Befehl in die Suchmaske eingegeben. Der Unterschied: Es wird nicht nach einem Begriff, sondern nach einer URL gesucht.
Für die Auffindung der im Index auffindbaren Subdomains genügt die Eingabe von „Site:URL“.
site:www.meinedomain.de
Wie lange dauert eine Indexierung?
Das erste Crawlen einer Website kann innerhalb von wenigen Tagen abgeschlossen sein. Erst danach werden die gecrawlten Inhalte indexiert. Dies kann einige Wochen in Anspruch nehmen. Das Einreichen der Seite ist jedoch keine Garantie dafür, dass der Crawler innerhalb von Minuten oder Tagen auf die Website kommt. Es dient lediglich als Hilfestellung und als Information an Google, dass Inhalte geändert wurden. Wann der Crawler die Website wieder besucht, hängt z. B. davon ab, wie viel Crawl-Budget Google der Seite zur Verfügung stellt und wann dieser das letzte Mal auf der Seite war.
Ob und wie lange es dauert, bis eine Website indexiert ist, hängt also von verschiedenen Faktoren ab:
- Wie oft die Website gecrawlt wird
- Wie häufig die Website geändert wird
- Wie optimal die Lesbarkeit für Suchmaschinen ist
- Wie die Qualität der Seite ist (Geschwindigkeit, interne Verlinkungen, Inhalte der Seite etc.)
Die Indexierung verhindern
Seiten können nur über eine Suchmaschine gefunden werden, wenn sie indexiert sind. Dennoch kann es vorkommen, dass bestimmte Seiten nicht im Google Index aufgenommen werden sollen.
Gründe hierfür sind beispielsweise:
- Die Seite wurde nur als Landingpage für Google-Ads-Anzeigen erstellt und enthält identische Inhalte von einer Seite, die sich bereits im Google Index befindet.
- Die Seite ist in einer Test- oder Entwicklungsphase und befindet sich noch im Entwurf.
- Die Inhalte der Seite bieten keinen Mehrwert oder die Seite hat sehr wenig Content.
- Seiten, die nicht für die Öffentlichkeit bestimmt sind, beispielsweise nur für Mitarbeiter oder Mitglieder (z. B. bei Sportstudios).
- Seiten, die zum Conversiontracking genutzt werden (Danke-Seiten, Kaufbestätigsseiten).
Möchte man die Indexierung verhindern, besteht die Wahl zwischen 4 verschiedenen Möglichkeiten:
Der Meta-Tag Noindex
Mit diesem Meta-Tag bekommt der Crawler den Befehl, die Seite nicht zu indexieren. Die meisten Crawler von Suchmaschinen halten sich zwar daran, jedoch handelt es sich bei diesem Befehl nur um eine Anweisung bzw. einen Hinweis, den Google trotzdem ignorieren kann. Der noindex-Tag sieht wie folgt aus:
<meta name=”robots” content=”noindex”/>
Die Robots.txt
Mit der Robots.txt lassen sich Crawler von bestimmten Seiten oder Verzeichnissen aussperren. Diese Textdatei legt den Bereich der Website fest, der gecrawlt werden darf.
| robots.txt | Funktion |
|---|---|
| User-Agent: * Disallow: / |
Die obere Zeile gibt an, für welchen Crawler bzw. Art von Crawler (z. B. Googlebot, Rytebot) der Befehl darunter gilt. Das Sternchen bedeutet in diesem Fall, dass der Befehl für alle Crawler gilt. Die untere Zeile gibt an, ob eine Website nicht gecrawlt (Disallow) oder gecrawlt (Allow) werden soll. In diesem Fall ist die Seite für alle Crawler gesperrt. |
| User-Agent: * Disallow: /unterordner1 Disallow: /unterordner2/unterordner/ |
Diese Angabe wird für die Sperrung einzelner Unterseiten verwendet. |
In der robots.txt-Datei sollte sich übrigens auch immer die URL zur Sitemap befinden. Dafür wird häufig die letzte Zeile als Ortsangabe für die XML-Sitemap genutzt. Um die Sitemap hinzuzufügen, reicht eine einfache Zeile aus:
User-Agent: *
Disallow:
Sitemap: https://www.domain.de/sitemap.xml
In der Search Console lässt sich die robots.txt per Robots-Testing-Tool außerdem prüfen.
Sperrung per .htaccess
Hierbei werden Crawler ausgeschlossen, indem ein Passwortschutz für die komplette Webseite oder auch für einige Verzeichnisse festgelegt wird. Auch Google empfiehlt das Blockieren von URLs mittels passwortgeschützter Serververzeichnisse, wenn man eine Indexierung verhindern möchte. Beachtet werden sollte jedoch, dass die Sperrung per .htaccess eher dafür gedacht ist, um eine ganze Website und nicht etwa einzelne Seiten zu sperren.
Canonicals
Per Canonical Tag kann doppelter Content im Index vermieden werden. Hierbei wird dem Crawler vermittelt, dass nur das Original statt der gefundenen Seite indexiert werden soll. So erhält der Crawler einen klaren Hinweis darüber, welcher Inhalt relevanter ist, wodurch eine Abstrafung für Duplicate Content effektiv verhindert wird.
Unfreiwillig de-indexiert
- Zunächst kann ein Wiederaufnahmeantrag, auch Reconsideration Request genannt, an Google gerichtet werden.
- Hat man sich selbst einiges zu Schulden kommen lassen, muss nachgewiesen werden, dass die Fehler behoben wurden.
- Ist man Opfer eines Hackers geworden, muss auch dies nachgewiesen werden.
- In den Webmaster Tools kann ein Antrag auf erneute Überprüfung gestellt werden.
Sind alle Informationen hinterlegt, kann es zwischen zwei und zwölf Wochen dauern, bis die Seite wieder im Index ist.
Bedeutung der Indexierung für SEO
Die Bedeutung der Indexierung ist für SEO immens. Denn das Indexieren einer Website ist die Basis für die Auffindbarkeit und gute Platzierungen in den Suchmaschinen und dementsprechend wichtig für die Suchmaschinenoptimierung (SEO). Smarte Technologien und Lösungen sorgen dafür, dass nicht lange auf das Crawling gewartet werden muss und die Seite schnell in den Index der jeweiligen Suchmaschine aufgenommen wird. Bis zu einem gewissen Maß kann dieser Prozess von Webmastern beeinflusst werden, damit die Seite an Sichtbarkeit gewinnt und möglichst weit oben an prominenter Stelle platziert wird. Onpage und Offpage Maßnahmen sowie holistischer Content spielen bei dem Ranking der Suchergebnisse eine enorme Rolle.
Wichtig ist, auf dem Laufenden zu bleiben. Da Google als Suchmaschine stetig weiter daran arbeitet, noch schneller und effizienter Ergebnisse zu liefern, ändert sich auch der Algorithmus stetig. Hat man Platz 1 der organischen Suchergebnisse für sich beansprucht, ist dieser nicht gleich garantiert. Ein einziges Update kann beispielsweise bereits dazu führen, dass die Website schlechter rankt. Als SEO Agentur helfen wir dabei, Spitzenplatzierungen zu erreichen und diese auch zu halten.

