Technisches SEO: Der ultimative Guide für die Basis aller Ranking-Erfolge
Digitales Marketing ist komplex und ständig im Wandel. Nach wie vor bleibt dennoch eines ein notwendiger Bestandteil: eine effektive Suchmaschinenoptimierung, kurz SEO. Technisches SEO (engl. technical SEO) ist dabei der Grundstein für eine erfolgreiche SEO-Strategie und bildet die Basis aller zukünftigen Erfolge der Sichtbarkeit deiner Website in der organischen Suche bei Suchmaschinen wie Google und Bing.
Im technischen SEO liegt der Fokus auf der Optimierung der Bestandteile einer Website, die den Suchmaschinen ermöglichen, eine Website effizient zu crawlen, zu indexieren und zu ranken. Bedeutet konkret, dass Google deine Website erst durchsuchen muss, um sie anschließend in den richtigen Kontext einzustufen sowie zu platzieren.
Dieser SEO Guide führt dich durch die wichtigsten Bereiche des technischen SEO und bietet eine Checkliste am Ende dieser Seite zur Umsetzung, damit du ein starkes Fundament für die Optimierung deiner Website aufbauen kannst.
Definition: Was ist technisches SEO?
Technisches SEO ist ein Teilbereich der Suchmaschinenoptimierung, der sich auf die Optimierung der technischen Aspekte einer Website konzentriert, um die Sichtbarkeit und Leistung in Suchmaschinen zu verbessern.
Im Gegensatz zur OffPage-SEO, die sich auf Linkaufbau konzentriert, ist technisches SEO ein wichtiger Teil der Onpage-SEO. Kern der technischen Optimierung ist der Fokus auf die Infrastruktur und Funktionalität einer Website sowie die Behebung von Fehlern und Warnungen, um sicherzustellen, dass Suchmaschinen-Crawler deine Website optimal durchsuchen können. So können deine Inhalte im richtigen Kontext in den Google Index aufgenommen werden und eine Platzierung für relevante Suchbegriffe erzielen.
Die Optimierung der Technik ist der wichtigste Teil der Website-SEO und bildet den Grundstein für deine Ranking-Ziele. Wenn SEOs vom Crawling und der Indexierung von Seiten sprechen, meinen wir damit, dass die Seiten, die über Suchmaschinen gut gefunden werden sollen, für Google-Crawler erreichbar, lesbar und einstufbar sind. Zusammenfassend bedeutet das also: Die Voraussetzung für Chancen auf eine gute Platzierung – also Sichtbarkeit auf Seite 1 – ist, dass deine Seiten crawlbar und indexierbar sind. Für ein stabiles Fundament lohnt sich die Zusammenarbeit mit einer KI-Agentur. Mit GEO wirst du auch in Chat- und Such-Assistenten leichter gefunden.
Wie wichtig ist die technische SEO wirklich?
Damit der Content deiner Website erfolgreich für Suchmaschinen optimiert werden kann, muss deine Seite zunächst technisch für Crawler optimiert werden. Die technische SEO bietet die Grundlage für den Erfolg bei Google & Co..
Aus diesen 4 Gründen ist die Optimierung der SEO Technik unerlässlich

Technisches SEO bildet ein solides Fundament für weitere Optimierungsmaßnahmen wie einer abgestimmten Content Strategie und Offpage SEO. Nur so kann die Gesamtperformance der Website steigen. Ohne technische SEO = keine Erfolge oder solche, die länger auf sich warten lassen.

Wenn technische Aspekte optimiert sind, wird die Website besser gecrawlt. Vernachlässigst du die technische SEO, können wichtige Seiten übersehen oder falsch indexiert werden, was sich negativ auf das Ranking der gesamten Website auswirkt. In SEO-Kreisen nennen wir das die Optimierung des Crawl-Budgets.

Die Nutzererfahrung wird im Rahmen der technischen SEO ebenfalls optimiert. Dazu gehören die Optimierung der Ladezeit, die korrekte Darstellung der Website auf verschiedenen Geräten und eine übersichtliche, benutzerfreundliche Struktur. Positive Nutzerfahrungen wirken sich auf die Absprungrate aus und sorgen für eine längere Verweildauer sowie zu höheren Conversion Rates. All diese Punkte führen letztendlich zu positiven Ranking-Ergebnissen.

Eine gut optimierte Website kann den entscheidenden Wettbewerbsvorteil bieten. Viele Websites weisen Schwächen in der technischen SEO auf. So kann deine Website eine höhere Platzierung erzielen und mehr Sichtbarkeit und Traffic generieren als die deiner Wettbewerber. Dies führt dann zu mehr Geschäftschancen, Verkäufen, Aufträgen.
Technisches SEO ist eine wichtige Komponente für den Erfolg deiner Website. Eine gut durchdachte technische Strategie stellt sicher, dass sowohl Suchmaschinen als auch Nutzer die Website optimal nutzen können, was nicht nur zur besseren Performance und einem höheren Ranking in den Suchergebnissen führt – sondern auch zu mehr Umsatz.
Kostenlose Beratung von Experten
Technical SEO als Voraussetzung für Top Rankings
Bei der Optimierung der SEO Technik werden verschiedene Aspekte einer Website überarbeitet. Technical SEO umfasst z. B. Maßnahmen wie die Optimierung von Seitenladezeiten, URL-Struktur, internen Verlinkungen, mobiler Benutzerfreundlichkeit und Sicherheit, um eine bessere Benutzererfahrung zu ermöglichen. Dieser Teil der Optimierung ist dabei kein alleiniger Ranking-Faktor, sondern vielmehr eine Voraussetzung, dass weitere SEO-Maßnahmen greifen können. Daher ist es wichtig, dass weitere Maßnahmen Bestandteil deiner SEO-Strategie und -Umsetzungen sind.
Wo liegen die größten Hebel bei der SEO Technik Optimierung?
Es gibt viele verschiedene Maßnahmen, die im Rahmen einer technischen SEO überprüft und optimiert werden können. Das Themenfeld ist sehr groß und beinhaltet auch Bilder SEO oder die Optimierung der Ladezeiten. Unsere Berufserfahrung hat gezeigt, dass diese 5 technischen Optimierungsmaßnahmen projektübergreifend die relevantesten sind und den größten Einfluss haben, weshalb wir uns in diesem Beitrag auf diese konzentrieren:
Website-Struktur: Eine gut strukturierte Website ermöglicht deinen Benutzern eine bessere Navigation und Benutzerfreundlichkeit. Google legt immer mehr Wert darauf, dass deine Nutzer zufrieden sind – also solltest du das auch tun.
Verwendung von Heading-Tags und Meta-Daten: Damit deine Website für Google gut lesbar ist, ist die Verwendung dieser Angaben sehr wichtig. Nur so kann Google den Kontext deiner Website verstehen und sie für relevante Suchbegriffe platzieren.
Fehlerhafte Links finden und beheben: Nicht nur in Bezug auf das Crawl-Budget ist die Optimierung der fehlerhaften Links innerhalb deiner Website wichtig. Erfahre, wie du sie findest, behebst und warum korrekte Links so wichtig für SEO sind.
Optimierung der technischen Dateien, die für das Crawling relevant sind: Was du genau bei der robots.txt, deiner Sitemap und beim Crawl-Budget beachten musst, zeigen wir dir auf dieser Seite.
Interne Duplikate erkennen und entfernen: Wir zeigen dir, wie du Duplikate auf deiner Website finden und beheben kannst. Dadurch schaffst du einzigartigen Content auf deiner Seite, was positive Einflüsse auf deine Rankings haben kann. Eine gezielte Content-Strategie ist Teil der wichtigsten Bausteine der Onpage-SEO.
In den folgenden Abschnitten gehen wir ins Detail und erklären dir, wie du verschiedene technische Bereiche deiner Website optimierst. Du hast keine Lust und Zeit, dich damit auseinanderzusetzen? Melde dich bei uns und erhalte einen kostenfreien technischen SEO-Audit und erfahre mehr über das Potenzial deiner Website.
Fordere jetzt dein technisches SEO Audit an!
Technical SEO-Basics
Für eine suchmaschinenoptimierte Website benötigst du unter anderem eine gute Struktur, die richtige Verwendung von Heading-Tags für optimierte Überschriften sowie individuelle Meta-Daten für jede einzelne Seite deiner Website und viele weitere SEO-Faktoren.
Achtung: Der Inhalt des Artikels richtet sich eher an Fortgeschrittene. Du möchtest mehr darüber wissen, wie du deine Website auch als Anfänger selber optimierst? In unserem Beitrag “Website für Suchmaschinen optimieren” erfährst du mehr dazu, wie du die richtigen Grundsteine für SEO-Erfolge legen kannst.
Die Struktur deiner Website optimieren
Die Seitenstruktur gehört zur OnSite-Optimierung und meint den Aufbau der einzelnen Seiten einer ganzen Website und die Gliederung dieser Seiten. Eine Unterseite sollte immer möglichst schnell mit wenigen Klicks erreichbar sein. Je länger der Pfad, desto mehr User springen auf dem Weg zur gewünschten Information ab. Studien zufolge ist eine Klickpfad-Länge von max. drei bis vier Klicks empfehlenswert. Auch die Unterteilung der Texte, die Navigation (Menü, Footer, ggfs. Seitenelemente) müssen übersichtlich gestaltet sein. Für eine optimale Nutzererfahrung empfiehlt es sich, nicht mehr als 7 Menüreiter zu verwenden.
Besuchern der Website sollte es so einfach wie möglich gemacht werden, die Texte einer Seite zu lesen. Lange Textwüsten sollten vermieden werden, dagegen ist die Verwendung von Überschriften, Zwischenüberschriften und sinnvollen, kurzen Absätzen empfehlenswert. Der Nutzer sollte die Seite auch einfach überfliegen können, um schnell die Antworten auf seine Fragen zu finden.
Die richtige Verwendung von Heading-Tags
Das Aussehen und der Inhalt einer Seite spielen für SEO eine wichtige Rolle, denn Google beurteilt die Qualität von Websites unter anderem auch auf der Basis der Nutzerfreundlichkeit. Eine sinnvolle Überschriftenstruktur im Fließtext ist nicht nur für die Suchmaschine, sondern auch für den Nutzer von Hilfe. Je besser die Überschriftenstruktur bereits Rückschlüsse auf das Thema der Seite erlaubt, desto einfacher fällt den Crawlern die Analyse der Inhalte und somit auch die Platzierung für die thematisch relevanten Keywords.
Für eine übersichtliche Hierarchie werden sogenannte Heading-Tags verwendet. Diese sind HTML-Tags und werden mit <h1> bis <h6> beschrieben. Dabei ist <h1> die Hauptüberschrift mit der höchsten Priorität. Je höher die Ziffer, desto niedriger die Hierarchie der Überschrift.
Wichtig dabei ist, dass diese Heading-Tags sinnvoll genutzt werden und nicht für einzelne Wörter wie „Leistungen“ oder Überschriften wie „Herzlich Willkommen auf unserer Website!“ verwendet werden. Der Content der Website sollte in kurze Textabschnitte mit Zwischenüberschriften gegliedert sein und dem Nutzer ermöglichen, ihn zu überfliegen.
So sieht die Gliederung der Überschriften aus
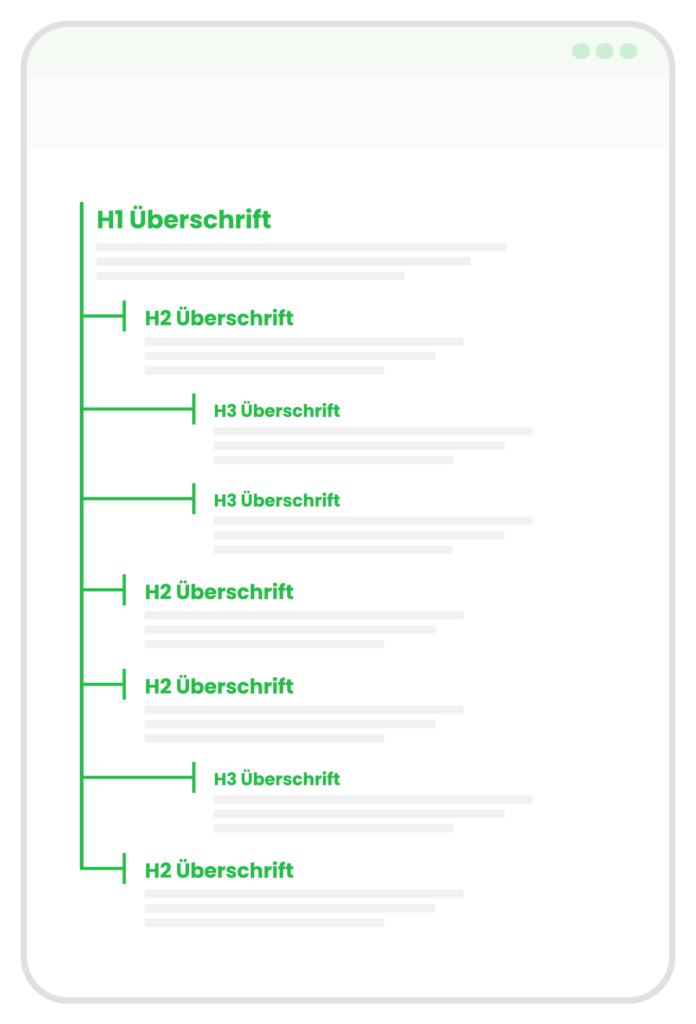
Das Heading Tag <h1> darf es nur ein einziges Mal auf der Seite geben. Darauf folgen die weiteren Tags in der richtigen, logischen Reihenfolge. <h4> sollte also nicht vor <h2> vorkommen. Die Farbe und Größe der Heading-Tags kann über CSS angepasst werden. In der Regel ist <h1> die größte und <h6> die kleinste Schriftgröße.
Überschriften und Titel, zum Beispiel im Footer, sollten nicht mit Heading-Tags versehen, sondern über CSS-Klassen ‚designed‘ werden.
Gute SEO Überschriften schreiben
Bei der Erstellung von Content ist es nicht wichtig, in ‚SEO-Überschriften‘ zu denken. Die Überschriften sollten für den Nutzer geschrieben sein und ihm dabei helfen, zu verstehen, worum es auf der Seite geht. Prinzipiell können folgende Punkte als Richtlinien gelten:
- Kurz und prägnant, 5 oder weniger Wörter
- Hoher Informationsgehalt
- Beginnt mit Keyword oder enthält Keyword
- Kann auch als Frage formuliert sein
- Der Nutzer versteht den gesamten Kontext, ohne den Artikel gelesen zu haben
- <h1> sollte das Keyword enthalten, welches auf der Seite fokussiert wird
Individuelle und optimierte Meta-Daten für jede einzelne Seite
Mit Hilfe der Angabe von sogenannten Meta-Daten („Tags“) kann im Rahmen der Suchmaschinenoptimierung die Lesbarkeit der Seite für Nutzer sowie Bots optimiert werden. Diese Meta Tags geben dabei Informationen zu einer Seite preis und befinden sich im Head-Bereich eines HTML-Dokuments, die für den Besucher der Website nicht direkt sichtbar sind.
In den meisten CMS sind diese Daten über zwei Felder einzubauen (Meta Title und Meta Description). Sollte dies nicht der Fall sein, müssen für jede einzelne Seite folgende Zeilen im Quelltext ergänzt werden:
<title>Ich bin der Titel dieser Seite </title>
<meta name=“description“ content=“Ich bin die Beschreibung des Contents dieser Seite.“/>
Achte dabei darauf, Title und Description immer und individuell für jede einzelne Seite zu schreiben. Sogenannte Meta-Keywords dagegen kannst du ignorieren, sie sind nämlich veraltet und müssen nicht eingebunden werden, da sie von Google ohnehin ignoriert werden.
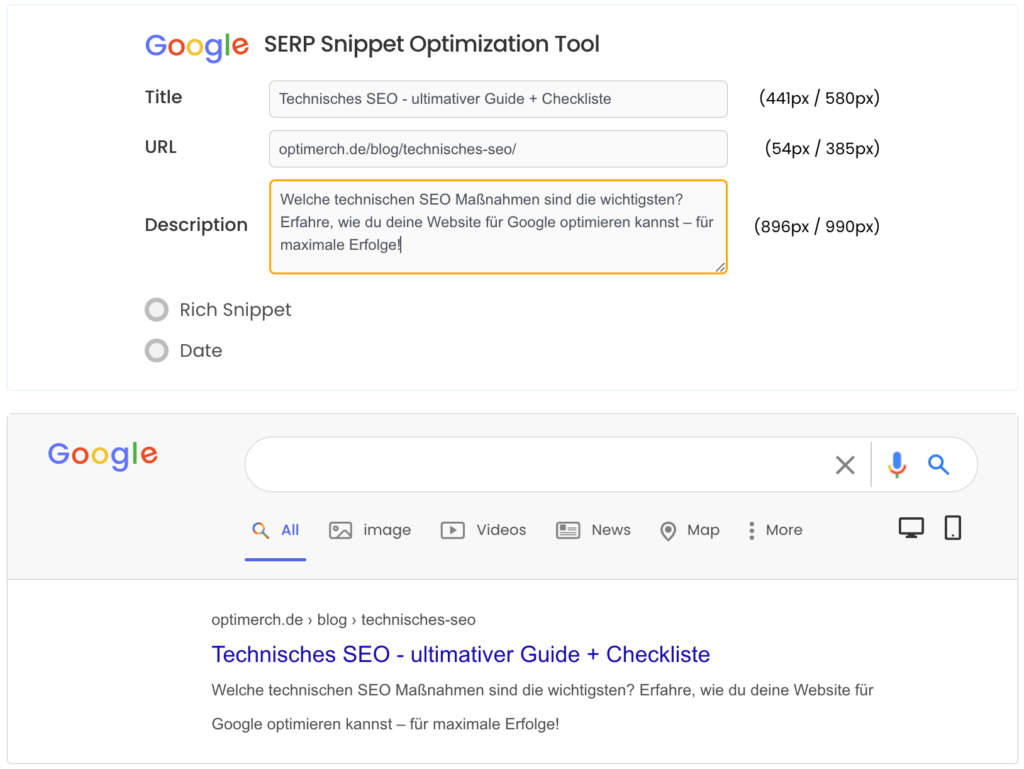
Hinweis: Der Titel sowie die Beschreibung sind die Angaben, die der Nutzer auf den Suchergebnisseiten der Suchmaschinen sieht. Der Seitentitel und die kurze Beschreibung sind also wichtige Rankingfaktoren. Die Wortwahl sowie Gestaltung dieser Angaben kann Einfluss auf die Klickrate haben und somit positive Effekte für Keyword-Rankings erzielen.
Für die maximale Zeichenlänge gilt kein konkreter Wert, es ist aber sinnvoll, sich an einem Richtwert zu orientieren. Je nach Device werden die Angaben unterschiedlich angezeigt. Google verwendet auf dem Desktop eine andere Schriftart als auf Mobilgeräten – daher unterscheidet sich die Pixelbreite. Der Title sollte maximal 524 Pixel (oder zwischen 50-60 Zeichen) lang sein. Die Description sollte 100-150 Zeichen lang sein. In der mobilen Suche werden ungefähr 110 Zeichen dargestellt, weshalb in den letzten Zeichen keine wichtigen Informationen enthalten sein sollten.
Mit dem SERP Simulator können Meta-Angaben getestet werden: https://serpsim.com/
Wusstest du schon, dass einige Suchmaschinen tatsächlich noch auf Meta-Keywords setzen? Google und Bing haben bereits vor mehreren Jahren veröffentlicht, dass Meta-Keywords nicht zur besseren Sichtbarkeit führen. Allerdings werden sie manchmal dafür genutzt, um Spam auszuschließen. Findet der Crawler das Keyword, das in den Meta-Keywords eingetragen ist, nicht in den Inhalten der Seite, kann dies zu schlechten Ergebnissen führen.
Nutze strukturierte Daten und Markups
Sogenannte strukturierte Dateien (Markups) können dabei helfen, dass Inhalte von Suchmaschinen besser ausgelesen und interpretiert werden können. Die Inhalte der Seite werden dann in Form von Rich Snippets ausgespielt, die sich vom Rest der Ergebnisse im Ranking abheben.
So sieht beispielsweise ein Markup-Code für ein FAQ aus:
<script type="application/ld+json">
{"@context": "https://schema.org",
"@type":"FAQPage",
"mainEntity":[{
"@type":"Question",
"name":"Was ist technisches SEO?",
"acceptedAnswer":{
"@type":"Answer",
"text":"Technisches SEO bezieht sich auf die Maßnahmen, die darauf abzielen, eine Website für Suchmaschinen einfacher lesbar, crawlbar und indexierbar zu machen."
}
}]
}
</script>
Und so sieht das ganze in den Suchergebnissen bei Google aus:

Mit dem Test für Rich-Suchergebnisse von Google kannst du übrigens ganz einfach austesten, ob dein Code funktioniert und auslesbar ist.
Schaffe eine lesbare URL-Struktur
Für SEO ist es sehr wichtig, dass du sogenannte ‘sprechende’ URLs nutzt. Das bedeutet, dass sie natürlich lesbare Begriffe beinhalten anstelle von Kürzeln, Ziffern etc. , mit denen weder Nutzer noch Crawler etwas anfangen können.
Halte also deine URLs so kurz und einfach wie möglich und erleichtere Nutzern sowie Suchmaschinen, dass sie direkt lesen können, worum es auf deiner Website geht. Trenne Verzeichnis-Namen sowie Begriffe in der URL immer mit einem Bindestrich (nicht mit einem Unterstrich). Verwende keine Leerzeichen oder andere Sonderzeichen zur Worttrennung.
Beispiel für eine sprechende URL:optimerch.de/blog/technisches-seo
Beispiele für eine nicht-sprechende URL:optimerch.de/blog/beitrag-20-21-2023/
domain.de/produkte/4587652-23-211/
Die Anatomie der URL sollte also wie folgt aussehen:
https://www.beispiel.de/thema/unterthema/seitentitel#anker
Protokoll, Domain, Top-Level Domain, Verzeichnisse, Seitentitel mit wichtigem Keyword, optional:anker
Außerdem sollte für die URL ausschließlich Kleinbuchstaben verwendet werden. In manchen Fällen führt die gleichzeitige Verwendung von Groß- und Kleinbuchstaben zu internen Duplikaten (Duplicate Content).
Beispiel: Sind beide URLs erreichbar, entsteht Duplicate Content:
https://www.test.de/blog
https://www.test.de/Blog
TO-DO’s:
- Schaffe schon im Voraus eine gute Struktur deiner Seite
- Verwende die richtigen Heading-Tags und beachte ihre Hierarchie
- Nutze individuelle Meta-Daten für jede Seite
- Schaffe lesbare URLs, die nur in Kleinschreibweise abrufbar sind
Optimierung des Crawlings und der Indexierung
1.1. robots.txt und Meta-Robots
Deine robots.txt-Datei steuert, welche Teile deiner Website von Suchmaschinen-Crawlern besucht werden dürfen. Stelle sicher, dass wichtige Seiten erlaubt sind und für die SEO unnötige Seiten blockiert werden. Verwende Meta-Robots-Tags, um spezifische Anweisungen für einzelne Seiten bereitzustellen.
Deine robots.txt sollte unter der URL domain.de/robots.txt abrufbar sein. Erhältst du eine leere, weiße Seite, ist das ein Hinweis darauf, dass keine robots.txt erstellt wurde. Um eine solche Datei zu erstellen, benötigst du Zugang zum Hosting deines Webservers und kannst dort in dem root-Ordner der Website eine Textdatei erstellen. Diese Textdatei beinhaltet häufig nur wenige Zeilen, wie beispielsweise:
User-agent: *
Disallow: /private/
Sitemap: https://www.deinewebsite.de/sitemap.xml
Doch was bedeuten diese drei Angaben?
User-agent
Der User-agent gibt an, welcher Bot die Anweisungen befolgen soll. Beispielsweise bezieht sich “User-agent: Googlebot” auf den Google-Suchmaschinenbot. “User-agent: *” bezieht sich auf alle Bots.
Disallow
Mit dem Disallow-Befehl kannst du bestimmte Teile deiner Website blockieren, damit Bots sie nicht durchsuchen. Beispielsweise kann “Disallow: /private/” dazu verwendet werden, Bots davon abzuhalten, das Verzeichnis “/private/” zu durchsuchen.
Sitemap
Zeige Google auf jeden Fall den “Standort” deiner XML-Sitemap. Dies kann Bots helfen, sie zu finden und die Website effizienter zu durchsuchen.
1.2. XML-Sitemaps
Eine XML-Sitemap listet alle wichtigen URLs auf deiner Website auf und erleichtert es Suchmaschinen, sie zu finden und zu crawlen. Erstelle eine XML-Sitemap und reiche sie bei Google Search Console und Bing Webmaster Tools ein.
Soll eine Seite nicht im Google Index aufgenommen werden, muss diese mit einem sogenannten noindex-Tag versehen werden. In Online-Shops sind diese Seiten i.d.R. Seiten wie Warenkorb, Kasse, Vielen-Dank-Seiten, Mein Konto, die im Google Index nichts zu suchen haben. Nicht ausschließen solltest du dagegen Seiten wie dein Impressum, Datenschutz, AGBs und den Widerruf. Rechtliche Seiten sollten indexiert werden sowie in der Sitemap auftauchen, da sie Trust-Signale sein können. In gängigen CMS steht diese Einstellung über das Backend zur Verfügung.
So sieht eine noindex-Angabe im HTML-Code aus:
<meta name="robots" content="noindex,follow"
Seiten mit der noindex-Kennzeichnung dürfen nicht in der Sitemap vorkommen (und werden häufig bereits durch die Umstellung auf noindex automatisch aus der Sitemap ausgeschlossen). Beachte, dass die Sitemap.xml stets aktuell gehalten wird.
1.3. Crawl-Budget optimieren
Crawl-Budget bezieht sich auf die Anzahl der Seiten, die ein Suchmaschinen-Crawler auf deiner Website innerhalb eines bestimmten Zeitraums besuchen kann. Die Optimierung des Crawl-Budgets ist ein durchaus komplexes Thema, da es viele Stellschrauben gibt, die verbessert werden können. Neben der Optimierung der robots.txt-Datei sowie der Sitemap gehört ebenso folgendes dazu:
- Korrektur von fehlerhaften internen Links (z. B. 301- oder 404-Links)
- Sicherstellen von schnellen Antwortzeiten/Ladezeiten
- Beseitigung von internen Duplikaten
All diese Themen können sehr technisch sein, viel Zeit in Anspruch nehmen und bei falscher Umsetzung vieles auf deiner Website kaputt machen. Daher lohnt es sich immer, einen Experten wie eine SEO Agentur zu Rate zu ziehen. Die oben genannten Schwerpunkte der technischen SEO erläutern wir dir aber gerne weiter unten auf dieser Seite.
Wusstest du schon?
Du kannst deine Crawling-Statistiken in der Google Search Console abrufen und einsehen, wie viele Crawling-Anfragen Google deiner Website zur Verfügung stellt. Weitere Informationen, zum Beispiel zur Erreichbarkeit deiner Website (Hoststatus), erhältst du ebenso in diesen Statistiken! Rufe dazu deine Search Console auf, klicke auf “Einstellungen” und Rufe unter “Crawling” deinen Bericht auf.

TO-DO’s:
- Stelle eine robots.txt-Datei zur Verfügung
- Nutze noindex-Tags für Seiten, die nicht indexiert werden sollen
- Erstelle eine Sitemap mit allen wichtigen Seiten
- Halte deine Sitemap immer aktuell
- Überprüfe interne Verlinkungen auf Fehler (Screaming Frog)
- Teste deine Ladezeit und erstelle keine duplizierten Inhalte
Fehlerhafte interne Verlinkungen optimieren
Sind die internen Verlinkungen deiner Website fehlerhaft, kann sich dies negativ auf die SEO deiner Website auswirken. Sie beeinträchtigen nicht nur die Nutzererfahrung, sondern sorgen auch dafür, dass Crawler auf Fehler stoßen, sodass das Crawl-Budget nicht optimal genutzt werden kann. Doch was ist mit fehlerhaften Links gemeint?
Wenn ein Nutzer auf einen Link deiner Website klickt und auf eine 404-Seite geführt wird, ist das mit eines der schlechtesten Dinge, die passieren können. Häufig ist dies der Fall, wenn eine Seite gelöscht oder die URL geändert wurde, der Link aber an Stellen im Text nicht ersetzt oder entfernt wurde. Was machst du selber, wenn du auf einen 404-Link klickst? Du verlässt die Seite, weil du nicht findest, wonach du gesucht hast und genau das tut der Crawler auch. Das sind negative Signale für Google.
Wie erkennt Google fehlerhafte Verlinkungen?
Jedes Mal, wenn ein Bot oder ein Nutzer eine Seite aufruft, sendet der Client (beispielsweise der Browser) eine Anfrage an den Server. Die Antwort des Servers beinhaltet neben anderen Informationen auch den sogenannten HTTP-Statuscode. HTTP steht für „Hypertext Transfer Protocol“ und ist ein dreistelliger Zahlencode, den der Server dem Client zurückgibt und somit den Status der Seite liefert. Diese Daten liest Google also aus. Insgesamt gibt es ca. 40 Statuscodes, jedoch sind nur einige wenige wirklich relevant für SEO und Google.
Die wichtigsten und SEO-relevanten Status-Codes
- 200 (Anfrage erfolgreich)
- 300 (permanente Weiterleitung) sind ok
- 302 (temporäre Weiterleitung) sieht Google nicht gerne
- 3xx (sonstige Weiterleitungen) sind ebenfalls nicht gern gesehen
- 404 (Not Found) sollten gar nicht vorkommen
- 5xx (Server Fehler) sollten gar nicht vorkommen
Der Großteil, wenn nicht sogar alle, der Seiten einer Website sollten den HTTP-Statuscode 200 zurückliefern. Das bedeutet nämlich, dass die Anfrage erfolgreich war und deine Seite im Browser erscheint. Der Statuscode 301 besagt, dass die angeforderte Ressource dauerhaft unter einer anderen URL zu finden ist. Besucher und Suchmaschinen werden also weitergeleitet. Deine Besucher merken diese Weiterleitung in der Regel nicht, aber dafür die Crawler. Durch die Weiterleitung wird das Crawlbudget doppelt aufgebraucht, weshalb die Korrektur von solchen Links wichtig ist.
301-Weiterleitungen sollten also intern nicht genutzt werden. Verschiebt sich der Inhalt auf eine andere URL, muss intern überall dort, wo die alte URL eingebunden war, die alte URL durch den neuen Link ersetzt werden.
Wie erkenne und beseitige ich fehlerhafte Verlinkungen?
Um falsche Verlinkungen zu vermeiden oder zu korrigieren, ist es wichtig, regelmäßige Audits der Website durchzuführen, um sicherzustellen, dass alle Links korrekt funktionieren. Es gibt verschiedene SEO-Tools (z. B. Screaming Frog), die dabei helfen können, fehlerhafte interne Links auf deiner Website zu identifizieren.
Du benötigst Unterstützung beim Identifizieren von falschen Links?
Duplicate Content erkennen und vermeiden
Duplicate Content sind Inhalte, die identisch auf mehreren Seiten vorkommen. Dieser kann sowohl intern als auch extern entstehen. Externer Duplicate Content meint beispielsweise die Duplikate, die entstehen, wenn ein Webseitenbetreiber die Inhalte von einer anderen Website ‚stiehlt‘. Interne Duplikate entstehen durch die mehrfache Verwendung von Text(abschnitten) innerhalb der eigenen Domain. Diese entstehen aber nicht nur, wenn zwei oder mehr Unterseiten den gleichen Text enthalten.
So kann Duplicate Content entstehen
- Druckansichten, die ebenso unter einer URL abrufbar sind
- Automatisch generierte PDFs
- Fehlerhafte Serverkonfiguration (modRewrite, Seite erreichbar mit und ohne www)
- Keine 301-Weiterleitung
- Seite ist über http und https erreichbar
- Seite ist mit und ohne Trailingslash „/“ am Ende aufrufbar
- Seite ist über Groß- und Kleinschreibung aufrufbar
- Seite ist über Parameter für z. B. Affiliate-URLs abrufbar
- Seite ist über /index.htm, /de/ und weitere Dinge, die CMS produzieren, abrufbar
- Umfangreiche Footer-Inhalte und Sidebars mit Textabschnitten
- Paginierungsseiten
Duplicate Content führt zwar nicht gleich, wie oft angenommen, zu einer Abstrafung durch Suchmaschinen. Es kann jedoch passieren, dass die Suchmaschine die falsche URL indexiert und somit die http- statt der https-Variante im Index landet. Wenn Google nicht entscheiden kann, welche Seite relevanter ist, werden sich mehrere Seiten im Ranking abwechseln und es entsteht eine Keyword-Kannibalisierung. Spätestens wenn mehr doppelte als einzigartige Inhalte auf einer Website eingebunden werden, ist Duplicate Content ein echtes Problem. Ziel sollte es sein, dass jeder Inhalt möglichst unter nur einer einzigen URL erreichbar und gleichzeitig größtenteils einzigartig ist.
Duplicate Content erkennen
Für die Analyse von Duplicate Content gibt es verschiedene Tools und Möglichkeiten, herauszufinden, an welchen Stellen Inhalte kopiert sind. Die einfachste Möglichkeit ist, eine Textstelle zu kopieren und bei Google einzugeben. In den Suchergebnissen werden dann die Websites angezeigt, die denselben Text verwenden.
In der Google Search Console ist ein Tool vorhanden, in dem eingesehen werden kann, welche Seiten bereits aus dem Index ausgeschlossen wurden, weil sie als Duplikate erkannt wurden. Diese findest du unter “Indexierung > Seiten” im Bereich “Warum Seiten nicht indexiert werden”.

Hierzu gibt es 3 verschiedene Einträge:
- Alternative Seite mit richtigem kanonischen Tag: hier muss nichts unternommen werden. Die Seite zeigt korrekt auf eine kanonische Seite, die indexiert ist.
- Duplikat – vom Nutzer nicht als kanonisch festgelegt: Es wurde ein Duplikat erkannt, ohne dass der Nutzer eine Anweisung hinzugefügt hat, dass es sich um ein Duplikat handelt. Google hat eine andere Seite als kanonische Seite für diese URLs eingestuft und wird sie daher nicht im Google Index aufnehmen.
- Duplikat – Google hat eine andere Seite als der Nutzer als kanonische Seite bestimmt: Die aufgelisteten URLs unter diesem Punkt enthalten einen Canonical Tag, der vom Websitebetreiber als solches eingestellt wurde. Google entscheidet hier aber, dass eine andere URL als kanonische Seite eingetragen werden muss und wählt stattdessen diese aus. Der durch den Nutzer eingerichtete Canonical Tag wird ignoriert.
Duplicate Content vermeiden
Im Prinzip sollte Duplicate Content gar nicht erst entstehen. Die Vermeidung fängt schon bei der Crawlingsteuerung an: Kopierte Seiten sollten intern nicht verlinkt werden und nicht in der Sitemap auftauchen, sodass Bots und Crawler diese gar nicht erst aufrufen.
Manchmal kommt es vor, dass du einer deiner Unterseiten ein neues Design verleihen möchtest. Dazu kopieren viele Website-Betreiber die ‘alte’ Seite und bearbeiten sie anschließend. Dabei wird oft vergessen, die neu erstellte Seite im Entwurfmodus zu bearbeiten, sodass beide Seiten gleichzeitig veröffentlicht und damit für Google erreichbar und indexierbar sind. Das gleiche Problem ergibt sich übrigens auch daraus, wenn du Seiten zusätzlich für Google Ads als Landingpage erstellst. Häufig werden dabei dieselben Inhalte, teilweise ganze Textabschnitte von bereits bestehenden Seiten eingebaut. Achte also unbedingt darauf, dass Seiten mit nahezu identischen Inhalten das noindex-Tag erhalten. (Zur Erinnerung: noindex bedeutet immer, dass diese Seiten nicht über die Suchergebnisse auffindbar sind).
Müssen Seiten mit denselben Inhalten dagegen unter verschiedenen URLs abrufbar sein, muss die Originalseite festgelegt und diese Information an die Bots der Suchmaschinen weitergegeben werden (Abschnitt weiter unten zu ‚Canonical Tags‘).
Seiten, die mit einer falschen URL bereits indexiert sind und für bestimmte Suchbegriffe ranken, sollten auf die richtige URL per 301-Redirect weitergeleitet werden. Textabschnitte aus wenigen Sätzen (wiederkehrende Textbausteine) oder sich wiederholende Elemente (z. B. Auflistungen) innerhalb einer Website sind in Ordnung.
Die Korrektur von Duplicate Content kann durch verschiedene Lösungen erfolgen:
- eine Seite, die identische Inhalte aufweist wie eine andere, intern nirgendwo verlinken
- kopierte Seiten auf noindex setzen
- kopierte Seiten auf die original URL weiterleiten, wenn die kopierte Seite bereits indexiert ist
- in wiederkehrenden Bausteinen wenig Text oder Formulierungsvarianten verwenden
- Canonical Tags einrichten
Duplicate Content beheben: Canonical Tags einrichten
Bei Kopien oder sehr ähnlichen Inhalten gibt das Canonical Tag an, welche URL einer Seite von Google indexiert werden soll, bei der es sich um das Original handelt. Das Tag wird im Head-Bereich eines HTML-Dokuments definiert und ist ein Hinweis für Suchmaschinen, dass der originale Inhalt auf der dort hinterlegten Seite zu finden ist und diese in den Suchergebnissen ausgegeben werden soll. Das Canonical Tag kann außerdem genutzt werden, um zu verhindern, dass Druckansichten, PDF- Versionen von Unterseiten oder Seiten mit wählbarer Schriftgröße im Index landen.
Beispiel:
Folgende Seiten haben denselben oder ähnlichen Content:
- https://domain.de/inhalt/
- https://domain.de/unsere-inhalte/
- https://domain.de/landingpage-fuer-adwords/
Eine (1) dieser URLs ist das Original. Alle diese URLs erhalten das Original als kanonische URL (Canonical Tag):
<link rel=“canonical“ href=“https://domain.de/inhalt/“ />
Achtung: Seiten, die eine andere kanonische URL erhalten als die eigene URL, werden nicht im Google Index aufgenommen. Die Information, dass es sich um eine Kopie handelt, sorgt dafür, dass Google diese nicht in den Suchergebnissen anzeigt. Seiten mit doppelten Inhalten, beispielsweise Städteseiten zu einem bestimmten Thema/einer Dienstleistung, die aber in den Suchergebnissen erscheinen sollen, benötigen individualisierte Inhalte.
Das Canonical Tag kann im Head per Code eingebaut werden. In Tools wie Yoast SEO kann die URL der Originalseite als kanonische URL in den Einstellungen der Seite hinzugefügt werden.
Überprüfe die Erreichbarkeit deiner Domain
Im Hinblick auf Duplicate Content sind besonders die korrekte Weiterleitung und die Betrachtung der Erreichbarkeit der Domain über verschiedene Versionen wichtig.
Der Statuscode einer gesamten Website oder aber auch von gezielten URLs kann beispielsweise über das folgende Tool überprüft werden: https://httpstatus.io/.
Für die Suchmaschinenoptimierung ist es wichtig, dass die Website nur über eine Version erreichbar ist. Das bedeutet, dass verschiedene Versionen korrekt weiterleiten müssen:
- https://www.beispiel.de/
- https://beispiel.de/
- http://www.beispiel.de
- http://beispiel.de
Nur eine dieser Versionen darf abrufbar sein, alle anderen Versionen müssen per 301-Redirect weitergeleitet werden. Es darf sich hierbei nicht um die temporäre Weiterleitung (302) handeln.
TO-DO’s:
- Alle internen Seiten sollten den Statuscode 200 zurückgeben
- Keine 3xx, 4xx, 5xx Seiten intern verlinken
- Nicht auf externe Seiten verlinken, die 3xx, 4xx, 5xx zurückgeben
- 301-Weiterleitungen für verschobenen Content einrichten
Technical SEO Checklist – alle wichtigen technischen SEO Maßnahmen im Überblick
- Schaffe eine gute Struktur deiner Website (Navigation, URLs)
- Verwende richtige Headingtags und beachte ihre Hierarchie
- Verfasse individuelle Meta Daten für jede einzelne Seite
- Stelle eine robots.txt mit den entsprechenden Angaben zur Verfügung
- Nutze noindex-Tags an den richtigen Stellen
- Erstelle eine Sitemap und halte sie aktuell. Reiche sie in der Search Console ein.
- Überprüfe interne Verlinkungen auf Fehler
- Teste deine Ladezeit und halte die Google Guidelines ein
- Richte 301-Redirects ein, wenn du Inhalte auf andere URLs verschiebst
- Vermeide Duplikate durch die Verwendung von Canonical Tags
Technische SEO Agentur: warum Outsourcing Sinn macht
Das war ganz schön viel, oder? Auch wenn du spätestens jetzt wissen solltest, worauf es bei der technischen Optimierung deiner Website ankommt, kann die technische Optimierung deiner Seite echt überwältigend sein. Für einen umfassenden Audit fehlen Unternehmen oft die richtigen Tools und Kapazitäten zur Umsetzung. Gerne führen wir eine unverbindliche SEO Analyse für dich durch, damit wir Schritt für Schritt überprüfen können, welche Optimierungsmaßnahmen ausstehen und Schwachstellen aufdecken sowie beheben können. Wir freuen uns auf deine Anfrage!
Bekannte SEO Tools




SEO Onpage und Offpage Checkliste
Den Download für unsere SEO-Checkliste gibt es hier:
Ihre Daten werden nach den Richtlinien unserer Datenschutzerklärung verarbeitet.

