Was ist ein Crawler?
Ein Crawler, auch bekannt als Webcrawler, ist ein automatisiertes Programm, welches das Internet durchforstet und Informationen zu Websites sammelt. Crawler analysieren die Inhalte und Struktur von Websites.
Vor allem im Kontext von Suchmaschinen wie Google spielen Crawler eine wichtige Rolle, auch, wenn dies nur ein möglicher Einsatzbereich von Webcrawlern ist. Webcrawler machen erst möglich, dass neue Websites in den Suchergebnissen gefunden werden können. Daher ist ein wichtiger Bestandteil einer erfolgreichen SEO-Strategie, den Zugriff von Crawlern auf die Website gezielt zu steuern und zu überwachen.

Wie funktioniert Crawling?
Crawler arbeiten aufgabenorientiert, indem sie sukzessiv eine Liste von URLs “abarbeiten” beziehungsweise analysieren. Diese URL-Liste wird auch als “crawl frontier” bezeichnet und ist der Startpunkt der Analyse der Webcrawler. Im Rahmen der Untersuchung wird prinzipiell allen Links gefolgt, die von der Start-URL ausgehen. Gestoppt wird diese Analyse durch das Linkattribut rel=”nofollow”, was einem Webcrawler signalisiert, dass einem Link nicht gefolgt werden soll. Eine weitere Begrenzung der Arbeit des Crawlers stellt das sogenannte Crawl Budget dar. Es definiert die Ressourcen eines Crawlers, die für die Analyse einer Website aufgebracht werden dürfen. Während des Crawling-Prozesses analysiert der Crawler den Inhalt und die Struktur der Websites.
Nicht nur für Google: die unterschiedlichen Arten von Crawlern:
Crawler sind weit mehr als nur das Rückgrat von Suchmaschinen. Obwohl sie oft mit dem Sammeln und Indexieren der riesigen Menge von Informationen im Internet in Verbindung gebracht werden, um diese durchsuchbar zu machen, geht ihre Bedeutung weit darüber hinaus. Diese automatisierten Programme durchforsten Netzwerke, um eine Vielzahl von Aufgaben zu erfüllen, von der Überwachung von Websites auf Änderungen bis hin zur Sammlung spezifischer Daten für Marktforschung und Analysezwecke. Ihre Einsatzmöglichkeiten erstrecken sich über diverse Felder und Sektoren, einschließlich Marketing, Forschung, Sicherheit und Content-Management. Dies verdeutlicht, dass Crawler eine zentrale Rolle in der Informationsgesellschaft spielen, indem sie Daten zugänglich, analysierbar und nutzbar machen – weit über die Grenzen der Suchmaschinenoptimierung hinaus. Mit dem Aufkommen generativer KI entstehen zusätzlich neue Antwortflächen und Signale. Wer dort sichtbar sein will, richtet Inhalte an GEO (Generative Engine Optimization) aus, damit sie von entsprechenden Systemen zuverlässig aufgegriffen werden.
Webcrawler (Suchmaschinen-Crawler)
- Zweck: Indizierung von Inhalten für Suchmaschinen.
- Funktionsweise: Durchsuchen des Internets, um Websites zu finden, sie zu analysieren und in einer Datenbank zu speichern. Sie folgen Links von einer Seite zur anderen.
- Beispiele: Googlebot (Google), Bingbot (Bing).
Site-Crawler
- Zweck: Spezifisch für eine Website oder ein Content-Management-System, um Inhalte zu indizieren oder zu aktualisieren.
- Funktionsweise: Ähnlich wie Webcrawler, aber beschränkt auf eine bestimmte Website oder ein internes Netzwerk.
- Anwendung: Überwachung von Website-Updates, Indizierung für interne Suchfunktionen.
- Beispiel: Screaming Frog
Content-Crawler
- Zweck: Extraktion und Analyse spezifischer Inhalte von Webseiten.
- Funktionsweise: Gezielte Suche nach bestimmten Informationen wie Preisen, Produktbeschreibungen oder Nachrichtenartikeln.
- Anwendung: Preisvergleiche, Marktanalysen, Medienüberwachung.
- Beispiel: idealo, Check24
SEO-Crawler
- Zweck: Analyse von Websites, um ihre Suchmaschinenoptimierung (SEO) zu verbessern.
- Funktionsweise: Untersuchung von Aspekten wie Seitenaufbau, Metadaten, Backlinks und Keywords.
- Anwendung: SEO-Beratung, Website-Audit.
- Beispiel: Ryte
Social Media Crawler
- Zweck: Sammeln von Daten aus sozialen Netzwerken und Foren.
- Funktionsweise: Erfassung von Beiträgen, Kommentaren, Likes und weiteren Interaktionen auf Plattformen wie Facebook, Twitter oder Reddit.
- Anwendung: Marktforschung, Sentiment-Analyse (Gefühlsanalyse), Trendbeobachtung.
- Beispiel: facebookexternalhit
Archivierungs-Crawler
- Zweck: Erstellen von Kopien von Websites, um ein Archiv des Internets oder spezifischer Websites zu erstellen.
- Funktionsweise: Systematische Erfassung und Speicherung von Webinhalten für historische Zwecke.
- Beispiele: Wayback Machine von Internet Archive.
E-Mail-Crawler
- Zweck: Sammeln von E-Mail-Adressen von Websites.
- Funktionsweise: Durchsuchung von Webseiten nach E-Mail-Adressen für Marketingzwecke oder Spam. Wird oft als unethisch betrachtet und kann gegen Datenschutzrichtlinien verstoßen.
- Beispiel: hunter.io
Webcrawler & SEO
Webcrawler spielen eine wichtige Rolle bei der Suchmaschinenoptimierung: Durch das regelmäßige Crawlen von Websites ermöglichen sie Suchmaschinen, aktuelle und relevante Informationen in ihrem Index bereitzustellen. Durch eine effektive Crawling-Strategie können Websitesbetreiber ihre Sichtbarkeit in den Suchmaschinen verbessern und mehr organischen Traffic generieren. Ein übergeordnetes Ziel von SEO ist es, die Website gut “crawlbar” zu machen.
Varianten des Webcrawlings:
- Focused Crawler: Im Gegensatz zu einem Webcrawler, der das gesamte Internet durchsucht, konzentriert sich ein Focused Crawler auf bestimmte Themen oder Domains. Er verwendet Algorithmen, um relevante Websites zu identifizieren und zu erfassen. Focused Crawler werden oft in spezialisierten Suchmaschinen oder in wissenschaftlichen Forschungsprojekten eingesetzt.
- Incremental Crawler: Ein Incremental Crawler ist darauf spezialisiert, nur diejenigen Websites zu crawlen, die sich seit dem letzten Crawling-Vorgang geändert haben. Dies ermöglicht es, die Aktualität der indexierten Informationen zu gewährleisten und den Ressourcenverbrauch zu reduzieren.
- Vertical Crawler/Harvester: Ein Vertical Crawler ist auf eine bestimmte Art von Content spezialisiert, wie z.B. Bilder, Videos oder Nachrichten. Er durchsucht das Internet gezielt nach diesen spezifischen Inhalten und indexiert sie entsprechend. Wenn solch ein Crawler auf der Suche nach einer bestimmten Art von Information das gesamte Internet durchforstet, z. B. nach E-Mail-Adressen von Firmen, wird der Crawler bei diesem Data Mining (= Daten-Förderung) auch Harvester (= Ernter) genannt.
So analysieren Suchmaschinencrawler eine Website
Der Crawling-Prozess von Suchmaschinencrawlern basiert auf Algorithmen, die den Webcrawler anweisen, wie er die Seiten durchsuchen und welche Informationen er erfassen soll. Algorithmen berücksichtigen Faktoren wie die Relevanz der Seiten, die Aktualität der Informationen und die Ressourcenverfügbarkeit. Ein Suchmaschinencrawler extrahiert Informationen wie Text, Bilder, Links und Metadaten, um sie später zu indexieren und in den Suchergebnissen der Suchmaschine aufführen zu können. Der Webcrawler folgt den Links auf den Seiten, um neue Seiten und Aktualisierungen bestehender Websites zu entdecken und erfassen.
Um das Crawling effizient zu gestalten, setzen Webcrawler auch Techniken wie das Caching von Websites ein, um bereits erfasste Seiten nicht erneut durchsuchen zu müssen: Beim Crawling werden normalerweise Ressourcen wie Bandbreite und Rechenleistung verwendet, um eine Seite herunterzuladen und zu analysieren. Im Cache können bereits gecrawlte Seiten zwischengespeichert werden, sodass der Webcrawler sie bei Bedarf nicht erneut herunterladen und analysieren muss.
Jede Suchmaschine nutzt eigene Crawler, um Seiten aus dem Internet für ihre Indizes zu kuratieren. So bekommen Websites z. B. Besuch vom Googlebot, Amazonbot, oder von Slurp aus dem Hause Yahoo. Zudem gibt es verschiedene Arten von Crawlern, die je nach ihrem Zweck und ihrer Funktionalität unterschieden werden können.

Wichtige SEO-Aspekte des Crawlings:
- Sichtbarkeit: Wenn eine Website nicht gecrawlt wird, kann sie nicht in den Suchergebnissen erscheinen und ist für Suchmaschinen unsichtbar, da sie nicht im Index der Suchmaschine auftaucht. Nur durch Crawling werden Seiten in den Suchergebnissen sichtbar.
- Aktualität: Durch regelmäßiges Crawling können Suchmaschinen feststellen, ob eine Website aktualisiert wurde. Aktualisierte Inhalte werden in der Regel höher in den Suchergebnissen platziert, da sie als relevanter und aktueller angesehen werden.
- Fehlererkennung: Beim Crawling können Suchmaschinen Fehler auf einer Website erkennen, wie z. B. defekte Links, fehlende Metadaten oder langsame Ladezeiten. Durch die Behebung dieser Fehler, z. B. durch Pagespeed-Optimierung, kann die technische SEO-Performance verbessert werden.
- Backlinks: Crawling ermöglicht es Suchmaschinen, Backlinks zu entdecken, die auf eine Website verweisen und Linkjuice weitergeben. Backlinks sind ein wichtiger Ranking-Faktor für Offpage-SEO und können die Sichtbarkeit und Autorität einer Website verbessern.
Die Crawling Statistik prüfen
Durch die Überprüfung der Crawling-Statistiken ihrer Domain können Website-Betreiber Einblicke in das Verhalten von Webcrawlern gewinnen und mögliche Probleme oder Verbesserungsmöglichkeiten identifizieren, um die SEO-Performance ihrer Website zu optimieren.
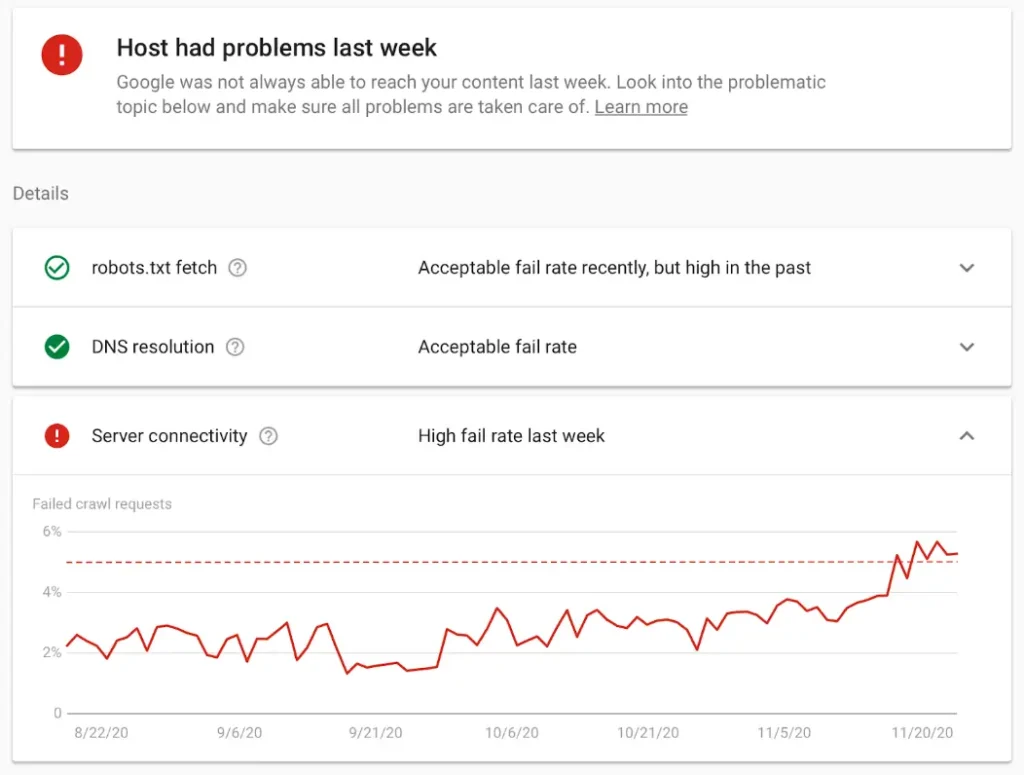
Die Crawling Statistik prüfen
Die Google Search Console bietet eine Reihe von Funktionen, um die Crawling-Statistik zu überprüfen. Hier lassen sich Crawling-Fehler, Crawling-Statistiken und die Anzahl der gecrawlten Seiten einsehen. Zudem gibt es umfassende Informationen zur Nutzerfreundlichkeit der Seite. Webmaster können außerdem die Log-Dateien ihres Servers analysieren, um Informationen über den Zugriff von Webcrawlern auf ihre Website zu erhalten. Die Log-Dateien enthalten Informationen wie IP-Adressen der Crawler, Zeitstempel und aufgerufene URLs.
Zugriff für Suchmaschinencrawler erlauben oder einschränken
Webcrawler können durch den Quelltext einer Website in ihrem Zugriff eingeschränkt werden oder Zugriffserlaubnisse erhalten: Durch die Verwendung einer robots.txt-Datei und Meta-Robots-Tags können Website-Betreiber den Zugriff von Crawlern auf bestimmte Teile ihrer Website steuern und kontrollieren. Dies kann nützlich sein, um sensible Informationen zu schützen, bestimmte Seiten auszuschließen oder die Indexierung von Duplikaten zu verhindern.
Was spricht für das Einschränken von Crawlern?
Es ist wichtig, die Einschränkung oder Erlaubnis des Zugriffs von Crawlern sorgfältig zu planen und umzusetzen, um sicherzustellen, dass die Website sowohl für Suchmaschinen als auch für Benutzer optimal funktioniert. Hierbei gibt es Fälle, in denen es sinnvoll sein kann, den Zugriff von Crawlern auf bestimmte Teile einer Website einzuschränken oder zu blockieren. Dies kann aus folgenden Gründen geschehen:
- Schutz sensibler Informationen: Wenn eine Website Informationen enthält, die nicht für die Öffentlichkeit bestimmt sind, sollte der Zugriff von Crawlern auf diese Informationen beschränkt werden, um ihre Verbreitung zu verhindern.
- Vermeidung von Duplikaten: Enthält eine Website viele gedoppelte Inhalte (z. B. dasselbe Produkt in verschiedenen Farben), kann der Zugriff von Crawlern auf diese Duplikate blockiert werden, um Probleme mit Duplicate Content zu umgehen – dabei sollten in dem genannten Beispiel noindex Tags vermieden werden: Eine noch effektivere Möglichkeit zum Umgang mit Duplikaten sind Canonical Tags.
- Ressourcenoptimierung: Manchmal ist eine Website durch besonders hohe Nutzerzahlen und Serveranfragen überlastet oder hat begrenzte Ressourcen. Der Zugriff von Crawlern auf bestimmte Teile der Website kann beschränkt werden, um Ressourcen zu schonen und die Leistung der Website zu verbessern.
Robots.txt-Datei:
Die Robots.txt-Datei ist eine Textdatei, die im “Stamm”-Verzeichnis (= Root) einer Website angelegt wird. Sie enthält Anweisungen für Webcrawler, welche Teile der Website sie crawlen dürfen und welche nicht. Die Datei kann spezifische Verzeichnisse, Dateien oder ganze Bereiche einer Website ausschließen. Crawler lesen zuerst die Robots.txt-Datei, um zu sehen, ob sie Zugriff auf bestimmte Bereiche der Website haben.
Beispiel einer Robots.txt-Datei
In diesem Beispiel wird allen Crawlern der Zugriff auf das Verzeichnis “/ausgeschlossene-unterseite/” verweigert, außer auf das Unterverzeichnis “/erlaubte-unterseite/”.
User-agent: *
Disallow: /ausgeschlossene-unterseite/
Allow: /erlaubte-unterseite/
Ein paar Website-Betreiber verweigern Crawlern von künstlichen Intelligenzen den Zugriff auf Ihre Inhalte, in der Robots.txt-Datei sieht das wie folgt aus:
User-agent: GPTBot
Disallow: /
#Uber Metrics
User-agent: um-IC
Disallow: /
#Googles generative AI crawlers
User-agent: Google-Extended
Disallow: /
Meta-Robots-Tags
Meta-Robots-Tags sind HTML-Tags, die in den Quelltext einer Website eingefügt werden können, um Crawlern Anweisungen oder zusätzliche Informationen zu Elementen zu geben. Websites können einen Meta-Robots-Tag enthalten, in dem sich verschiedene Attribute definieren lassen. Das Content-Attribut beispielsweise steuert, ob die Inhalte in den Suchergebnissen erscheinen dürfen oder nicht. Es gibt verschiedene Anweisungen, die im Tag erfasst werden können:
- noindex: Die Seite soll nicht in den Suchmaschinenindex aufgenommen werden.
- nofollow: Crawler sollen den Links auf der Seite nicht folgen.
- noarchive: Suchmaschinen sollen keine archivierte Version der Seite anzeigen.
- nosnippet: Suchmaschinen können keinen Auszug (Snippet) der Seite in den Suchergebnissen anzeigen.
Beispiel eines Meta-Robots-Tags:
<meta name="robots" content="noindex">
In diesem Beispiel wird Bots wie dem Googlebot mitgeteilt, dass die Seite nicht indexiert werden darf.
Fazit zu Crawlern
Die Bedeutung von Webcrawlern für Suchmaschinen und SEO sollte nicht unterschätzt werden. Crawler sind entscheidend für die Indexierung von Websites und die Bereitstellung relevanter Suchergebnisse für Benutzer. Sie ermöglichen es Suchmaschinen, Websites zu durchsuchen, zu analysieren und zu verstehen, um den Usern relevante und qualitativ hochwertige Suchergebnisse zu liefern. Durch die optimale Bereitstellung von Zugriffs-Erlaubnissen, Robots.txt und Ressourcen für Crawler können Website-Betreiber ihre Sichtbarkeit in den Suchmaschinen verbessern und ihre SEO-Bemühungen effektiver gestalten.
Darüber hinaus spielen Crawler eine wesentliche Rolle in einer Vielzahl von anderen Bereichen, die über SEO hinausgehen. Sie sind beispielsweise unerlässlich für das Sammeln von Daten für die Markt- und Sentiment-Analyse, das Monitoring von Wettbewerber-Websites, die Archivierung von Webinhalten und die Verbesserung der Nutzererfahrung durch das Erfassen und Analysieren von Benutzerinteraktionen und -feedback. Ihre Vielseitigkeit und Fähigkeit, große Mengen von Webinhalten systematisch zu erfassen und zu verarbeiten, macht Crawler zu einem unverzichtbaren Werkzeug.

