Was ist die Robots.txt?
Die robots.txt-Datei ist eine einfache Textdatei, die es Website-Betreibern erlaubt, zu steuern, welche Teile ihrer Website von Suchmaschinen indexiert werden sollen und welche nicht.
Eine robots.txt-Datei funktioniert gewissermaßen als “Verkehrsregler” für Bots: Sie bestimmt, welche Teile der Website sichtbar sein sollen. Diese Datei spielt eine entscheidende Rolle bei der Suchmaschinenoptimierung, da sie ermöglicht, die Indexierung einer Seite zu optimieren.
Aufbau und Inhalt einer robots.txt-Datei
Durch gezielte Anweisungen kann der Zugriff auf bestimmte Bereiche einer Website erlaubt oder verboten werden, was für die Suchmaschinenoptimierung von entscheidender Bedeutung ist.
- User-agent: Googlebot
- Disallow: /versteckter-bereich/
- Allow: /oeffentlicher-bereich/

1. User-Agent Anweisungen
User-Agent-Anweisungen definieren, welche Bots die nachfolgenden Regeln befolgen sollen. Das *-Zeichen wird ausgewählt, wenn die darauf folgenden Anweisungen für jeden Bot gelten sollen.
User-agent: Googlebot
Disallow: /kein-zugang/
User-agent: *
Disallow: /kein-zugang/
2. Disallow-Anweisungen
Die Disallow-Anweisungen geben an, welche Teile der Website für den spezifizierten Bot nicht zugänglich sind. Dies verhindert, dass bestimmte Seiten indexiert werden.
User-agent: *
Disallow: /kein-zugang/
3. Allow-Anweisungen
Im Gegensatz dazu erlauben Allow-Anweisungen den Zugriff auf bestimmte Bereiche, selbst wenn zuvor Disallow-Anweisungen eingesetzt wurden.
User-agent: Bingbot
Allow: /kein-zugang/
4. Sitemap-Anweisungen
Weitere wichtige Anweisungen einer robots.txt
- $ – Ende eines URL-Pfades: Die $-Anweisung wird verwendet, um das Ende eines URL-Pfads zu kennzeichnen. Dadurch wird angezeigt, dass nur exakte Übereinstimmungen blockiert oder erlaubt werden sollen.
- # – Kommentare: Die #-Anweisung wird verwendet, um Kommentare in der robots.txt-Datei einzufügen. Alles nach dem #-Zeichen wird von den Bots ignoriert.
- * – Platzhalter: Das *-Zeichen wird als Platzhalter verwendet und kann in User-Agent oder Disallow-Anweisungen eingesetzt werden.
# Es folgen Beispiele:
User-agent: *
Disallow: /kein-zugang$
Disallow: /*bilder/
Was ist ein User-Agent?
Der Begriff “User Agent” bezieht sich auf eine Identifikationskennung, die von jedem aktiven Teilnehmer im Internet genutzt wird, sei es Mensch oder Maschine. Bei menschlichen Benutzern enthält diese Kennung Informationen wie den Browsertyp und die Betriebssystemversion, wohingegen bei Maschinen, insbesondere Webcrawlern oder Bots, der User-Agent String dazu dient, ihre Identität und Funktionalität zu offenbaren.
Die robots.txt enthält Informationen darüber, welche User-Agents auf die Inhalte der Seite zugreifen dürfen und welche nicht.
Ein Beispiel hierfür wäre die Nutzung von “User-agent: AhrefsBot” und “User-agent: Googlebot” in der robots.txt-Datei, um bestimmte Seiten für Google oder SEO-Tools gezielt zu sperren. Ein typischer Anwendungsfall kann sein, wenn man vor einem GoLive einer neuen Unterseite dies testen möchte, sie aber noch nicht im Index der Suchmaschine landen soll. Zusätzlich kann die robots.txt genutzt werden, um gezielt bestimmte Tool-Crawler auszuschließen.
Der Platzhalter “*” (“User-agent: *”) kann verwendet werde, um allgemeine Anweisungen für alle Bots zu geben.
Wo findet man die robots.txt-Datei?

Warum ist die robots.txt-Datei wichtig für SEO?
Die robots.txt-Datei ist eine der ersten Dateien einer Website, die von Suchmaschinen-Bots gelesen wird. Mit dem Auslesen dieser Datei beginnt die Analyse der Website-Inhalte durch den Bot. Durch präzise Angaben kann definiert werden, welche Teile einer Websitezugänglich und indexierbar sind, während andere Bereiche bewusst ausgeschlossen, also für Crawler nicht zugänglich gemacht werden.
Für die Suchmaschinenoptimierung ist es wichtig, dass für jede Website eine robots.txt-Datei erstellt wird, um sicherzustellen, dass nur relevante Seiten (und damit ihre Inhalte) im Index von Suchmaschinen landen. Seiten, die geschützt werden und nicht indexiert werden sollten, sind beispielsweise Warenkorb-, Checkout- oder Admin-Seiten.
Crawl Budget optimieren
Das “Crawl-Budget” definiert die Ressourcen, die Google während eines Besuchs einer Website einsetzt. Der genaue Aufwand kann sich in Abhängigkeit vom Umfang und dem Zustand einer Website unterscheiden.
Da das Crawl-Budget begrenzt ist, kann eine Überschreitung der Seitenanzahl dazu führen, dass nicht alle Seiten indexiert oder bei Aktualisierung neu gecrawlt werden. Die Nicht-Indexierung wiederum führt dazu, dass diese Seiten in den Suchergebnissen nicht erscheinen.
Die gezielte Blockade unnötiger Seiten mithilfe der robots.txt-Datei ermöglicht es dem Googlebot (dem Web-Crawler von Google), mehr Crawl-Budget für relevante Seiten zu verwenden. So kann die Platzierung wichtiger Seiten in den Suchergebnissen beeinflusst werden. Mehr zur Crawl-Budget-Optimierung erklären wir in unserem Lexikonartikel.
Doppelte und nicht veröffentlichte Seiten ausschließen
Doppelte, nicht veröffentlichte und unerwünschte Seiten sollten unbedingt von Suchmaschinen-Bots ausgeschlossen werden, um Crawling-Ressourcen effizient zu nutzen und Probleme mit Duplicate Content oder irrelevanten Suchergebnissen zu vermeiden. Solche Seiten entstehen häufig durch Testumgebungen, Entwürfe, interne Suchergebnisse, Login-Seiten oder mehrere URL-Varianten einer Seite. Diese Seiten müssen zwar existieren, aber sie sollten nicht indexiert und in den Suchmaschinen gelistet werden.
Mithilfe der robots.txt-Datei können diese Seiten gezielt vom Crawling ausgeschlossen werden, beispielsweise durch das Sperren des Verzeichnisses /test/ oder von URLs mit bestimmten Parametern. Um jedoch sicherzustellen, dass solche Seiten auch nicht indexiert werden, sollten zusätzlich noindex-Anweisungen im Meta-Tag oder HTTP-Header verwendet werden, da die robots.txt-Datei allein die Indexierung nicht verhindert, wenn externe Links auf diese Seiten verweisen.
Ressourcen ausschließen
Unter bestimmten Umständen ist es angebracht, Inhalte wie PDFs, Videos und Bilder von den Suchergebnissen auszuschließen. Dies kann erfolgen, um die Vertraulichkeit dieser Inhalte zu wahren oder um den Fokus von Google auf bedeutendere Inhalte zu lenken.
Eine unzulängliche oder fehlerhafte Konfiguration der robots.txt kann jedoch verheerende Auswirkungen auf die Sichtbarkeit einer Website haben. Fehlende Anweisungen können zu einer unnötigen Indexierung von Inhalten führen, während zu restriktive Einstellungen dazu führen können, dass relevante Inhalte von den Suchmaschinen ausgeschlossen werden.
Checkliste zur Erstellung der robots.txt-Datei
1. Analyse der Website-Struktur
Es ist wichtig, die Bereiche einer Website zu identifizieren, die für Suchmaschinen-Bots zugänglich sein sollen, während gleichzeitig sensible oder irrelevante Bereiche ausgeschlossen werden sollen. Denn es kann vorkommen, dass Website-Betreiber unbeabsichtigt wichtige Teile ihrer Website blockieren, wodurch erhebliche Indexierungsprobleme auftreten. Dabei ist es ratsam, jede Anweisung sorgfältig zu überprüfen, um sicherzustellen, dass keine kritischen Bereiche gesperrt sind.
2. Festlegen von User-Agent Anweisungen
Webseitenbetreiber können Bots oder Bot-Gruppen definieren, für die spezifische Anweisungen gelten. Dazu wird “User-agent” gefolgt von einem Bot-Namen verwendet, um die Anweisungen zu spezifizieren.
3. Formulierung von Disallow- und Allow-Anweisungen
Um bestimmte Bereiche der Website für Suchmaschinen-Bots auszuschließen oder gezielt freizugeben, werden die Anweisungen Disallow und Allow verwendet.
- Disallow: Diese Anweisung wird genutzt, um Bots den Zugriff auf bestimmte Seiten, Verzeichnisse oder Dateien zu verwehren.
- Allow: Diese Anweisung erlaubt den Zugriff auf spezifische Seiten oder Verzeichnisse, die innerhalb eines sonst blockierten Bereichs liegen.
4. Einsatz von Wildcards für Flexibilität
Wildcards (*) können eingesetzt werden, um Platzhalter für Pfade oder Dateierweiterungen einzuführen, was eine flexible Steuerung über mehrere Bereiche ermöglicht. Ein unbedachter Einsatz von Wildcards kann jedoch dazu führen, dass wichtige Bereiche ungewollt gesperrt werden.
5. Hinzufügen von Kommentaren für Dokumentation
Das Einsetzen von #-Symbolen, um Kommentare einzufügen, erleichtert die Dokumentation und ist besonders nützlich für zukünftige Überprüfungen oder Änderungen.
6. Überprüfung der Syntax
Ein kleiner Syntaxfehler in der robots.txt-Datei kann dazu führen, dass die Bots die Anweisungen nicht richtig interpretieren und damit große Auswirkungen haben. Eine sorgfältige Überprüfung auf korrekte Syntax, Groß- und Kleinschreibung sowie Zeichen ist wichtig. Unklare oder inkonsistente Anweisungen können zu Missverständnissen führen. Es ist wichtig, eindeutige Direktiven zu setzen.
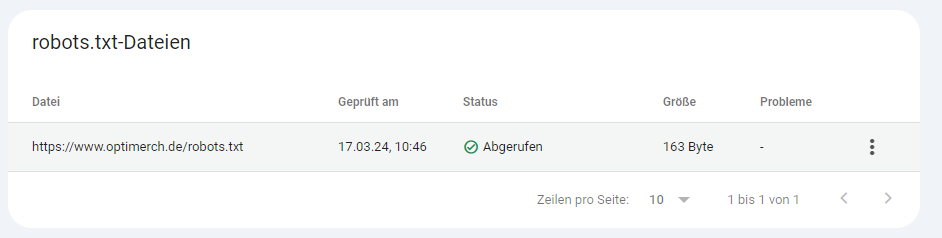
In der Google Search Console kann überprüft werden, ob die Robots.txt erkannt wird oder Probleme mit der Datei bestehen. Unter den Einstellungen in der Google Search Console kann man die Crawling-Statistiken einsehen und den Bericht abrufen.

Ein erfolgreich abgerufener Bericht der robots.txt-Datei sieht in der Google Search Console folgendermaßen aus:
7. Platzierung im Wurzelverzeichnis
Die robots.txt-Datei muss exakt im Wurzelverzeichnis platziert werden, um von Suchmaschinen-Bots erkannt zu werden – nicht in einem Unterordner. Das genaue Format als txt-Datei und der spezifische Ort sind entscheidend, andernfalls wird sie nicht berücksichtigt.
8. Regelmäßige Überprüfung und Aktualisierung
Die Punkte dieser Checkliste sollten nicht nur bei der Erstellung, sondern auch bei der kontinuierlichen Pflege der robots.txt berücksichtigt werden. Regelmäßige Überprüfungen gewährleisten, dass die Datei die gewünschte Kontrolle über die Indexierung aufrechterhält.
Bei Änderungen an der Website-Struktur oder -Inhalten ist eine Aktualisierung der robots.txt-Datei unerlässlich. Fehlende Updates können dazu führen, dass neue Inhalte nicht korrekt indexiert werden oder dass nicht mehr relevante Bereiche blockiert sind.
Zusätzlich bietet es sich an, verschiedene Optionen zur Überprüfung des robots.txt-Markups zu nutzen.
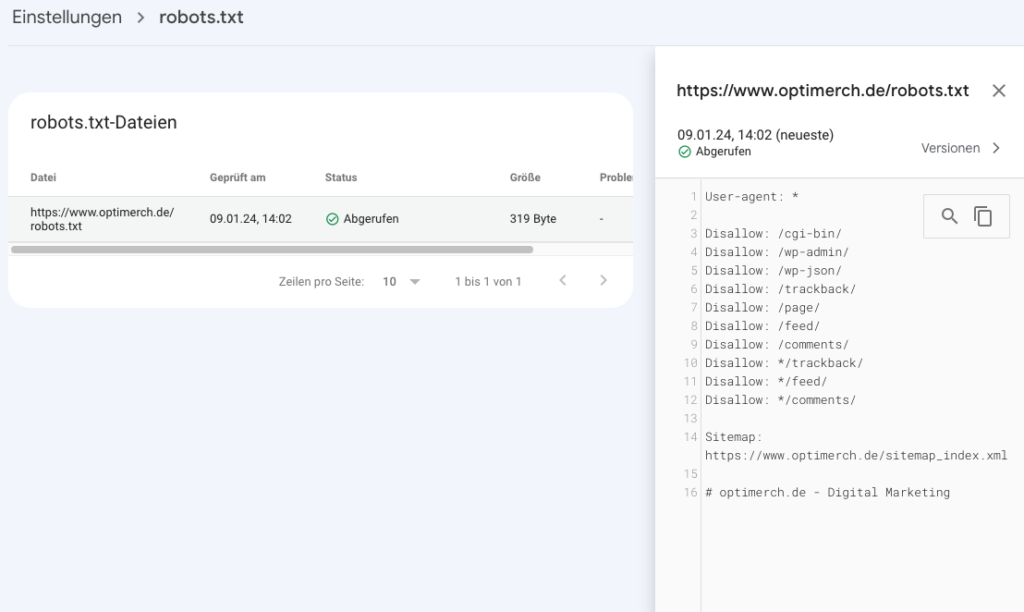
Dabei sollte darauf geachtet werden, dass trotz expliziter Ausschlüsse in der Robots.txt dennoch Seiten von Suchmaschinen indiziert werden, wenn andere Signale das Crawling als sinnvoll erscheinen lassen. Ein ganzheitlicher Ansatz ist erforderlich, um widersprüchliche Signale zu vermeiden.
Beispiel: Wenn eine Seite (beispiel-webseite.com/test) in der Robots.txt-Datei zum Disavow markiert ist, aber diese URL mit einem “follow”-Link von sehr vielen internen Seiten verlinkt wird, interpretieren Suchmaschinen dies sehr wahrscheinlich als Hinweis auf die Wichtigkeit der Seite und indexieren sie trotz des Ausschlusses.
Fazit
Zusammenfassend lässt sich sagen, dass die robots.txt-Datei eine wesentliche Rolle in der Suchmaschinenoptimierung spielt. Sie agiert im Hintergrund als eine Art Wächter, der den Zugriff von Suchmaschinen auf bestimmte Bereiche einer Website steuern kann. Obwohl sie auf den ersten Blick eher unscheinbar erscheinen mag, besitzt sie ein erhebliches Potenzial, die Sichtbarkeit und das Rankingeiner Website in den Suchergebnissenpositivzu beeinflussen.
Es ist wichtig zu verstehen, dass sie nicht alle Indexierungsprobleme lösen kann, aber eine sorgfältig konfigurierte robots.txt-Datei ist ein entscheidender Faktor für eine erfolgreiche SEO-Strategie. In der Praxis zeigt sich, dass eine angemessen gepflegte robots.txt-Datei unerlässlich für die Optimierung und den Schutz einer Website ist.

